虚拟网络杂谈
讲一讲虚拟机,docker之类的各种虚拟网络连接的乱七八糟的东西,还有一些做网安课设时遇到的问题
scapy的使用
这个算是最简单的点了
这个库还挺好用的,可以简单地拼接各层协议,并且自动寻找出口路由选择源IP地址,不清楚各字段的话可以show方法展示一下,然后在挨个print出来就行,比如ICMP的request和reply请求,show的时候显示的是字符串,但是你实际上打印出来会发现确实是一个数字,8代表request,0代表reply
当主机有多个网络出口的时候,这个库能自动的根据设置的dst ip查路由表,然后走对应的网卡出口,并且还能把src ip改成对应出口的ip,Mac地址什么的也不在话下
这里学到了一个好用的命令ip route get x.x.x.x,能直接查看ip对应的路由出口网卡,行!
然后发现了我一直以来的一个认知误区,我一直以为,比如我在局域网内的ip是192.168.68.10,在192.168.68.0/24这么个网段下,那么我访问自己的ip就会从局域网网卡出去,通过局域网路由在给我发回来,只有127.0.0.1这种类型的ip才会走本地的环回口,然而事实却是路由表把每个网卡出口对应的ip都记为本机了,也就是访问192.168.68.10会直接发到loopback上,不会从ethxx发出去再接回来。当然,访问192.168.68.11就会从局域网以太网口上走
说起来也是,如果本地路由表查不到192.168.68.10是本机的话,就算是发到局域网里又还回来了,也不能确定这个包是不是自己收啊,所以一开始就之前确定是自己收丢环回口上转去了
补充一下路由规则,当需要发送一个包时,需要先检查自己是否拥有该ip,若拥有则直接走环回口(但即使直接走环回口,源ip不一定是127.0.0.1,而是发起请求时访问的那个本机持有的ip),若不拥有,则查看路由表寻找出口,若路由表中无对应项则发送至默认网关
ICMP响应问题
scapy发出去的ICMP包似乎有点问题,不知道是我属性赋值没加齐还是怎么,从wireshark上抓包可以看到发出去的每个ICMP请求包都会有一个响应包,但wireshark并不会将该包认定为是scapy发出的ICMP请求包的响应,所以实验中有一个自己发scapy来实现traceroute的功能不太实现的了。感觉不是NAT的问题,因为如果是NAT的问题物理机上也不能用脚本跑通才对。
应该是请求和应答之间出了什么问题,使得这个请求和应答不能一一对应,导致物理机并不会把收到的请求发给虚拟机,所以在虚拟机中无法进行试验。而在物理机中不知道为什么,由于ttl为0导致的应答报文似乎能给正确的接受到,但同样的无法匹配正常的响应,所以traceroute会在终点时收不到对应回复
但是杨老师对1.1.1.1发起请求的时候得到了非常正确的结果,我也能复现,对于1.1.1.1这个ip ICMP的响应是能正确的对上的,看来是上层网络还有些奇怪的不可抗力,不知道怎么排障了
桥接、桥接与桥接
讲述的是docker的桥接和VM的桥接不是一个概念,然后在由于互联网上错综复杂的各种原理解释让我认为他们两是一个概念,再最后绕城一团乱麻故事
VM桥接
这个是我对桥接最初的理解,是VMware等虚拟化软件中提到的桥接,逻辑网络拓扑如图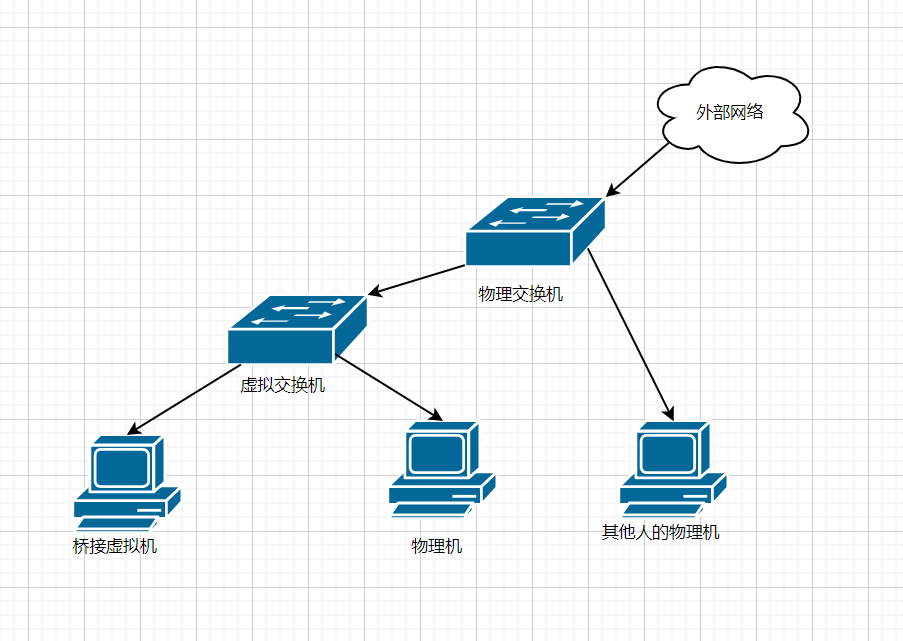
对于VMware来说这个虚拟交换机就是默认的一个叫VMnet0的虚拟网络,不过我桥接的时候并没有找到对应的网卡,如果能监听该网卡的流量就可以实现对虚拟机对外流量的全部监听
对于桥接的工作原理,网上有很多说法,我比较认同的是通过给物理网卡加驱动,能同时分配多个ip地址,然后将网卡运行在混杂模式下,对多个Mac地址进行匹配进行处理,就做到了一个虚拟交换机的效果,就有一种把虚拟机给直接暴露出来,平行于物理机的感觉
桥接出来的机器可以通过像物理路由器寻求DHCP来分配一个和物理机同一网段的IP,这样子就能被该局域网的其他主机直接探测到,比如图中的_其他人的物理机_,表现出来的形式就是该局域网中增加了一台机器
但是事情绝不会这么简单,桥接网上的桥接解释还有第二种形式,长这个样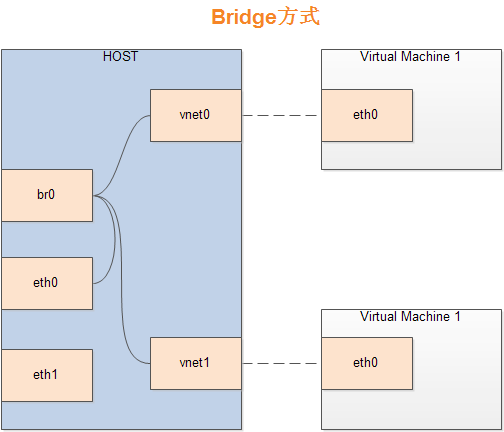
这和接下来即将提到的docker桥接的模式图很像,且这里的虚拟网桥还多出来了很多的网卡设备,这也只有在docker的桥接中能看到类似的设备,一度令我十分困惑
现在我觉得合理的解释是图中的网桥,即br0,vnet0,vnet1等网卡设备,都在VMware中被抽象成了一个VMnet0的虚拟交换机,但这些设备通过巧妙的实现并不能在主机中通过ipconfig等命令查看到,对用户隐藏了起来,但这其实是上文中虚拟交换机的实际实现形式
docker桥接
docker服务在启动之后会创建三个网络服务,VMware也会创建三个,他们的名字很像,可惜完全不是一一对应的关系
docker会创建bridge,host和none三种模式,对于bridge模式,Docker在安装时会创建一个名为docker0的虚拟网桥,每次启动一个docker会在物理机上装一个对应的vethxxx,docker的eth0就去连接物理机的vethxxx,这个操作被称为_veth pair_,由于每个docker都是一套全新的命名空间,因此需要使用该方案进行跨命名空间的通信,然后再通过vethxxx连接docker0,并通过该网桥访问外部网络,若多个docker接入同一个网桥(如docker0),则其可以在该网桥的局域网内互联,也可以手动配其他的网桥,这样子的网桥会以br-xxxx命名,可以用brctl show命令查看当前网桥和哪些网卡相连
这个图我就不画了,抄一个,一目了然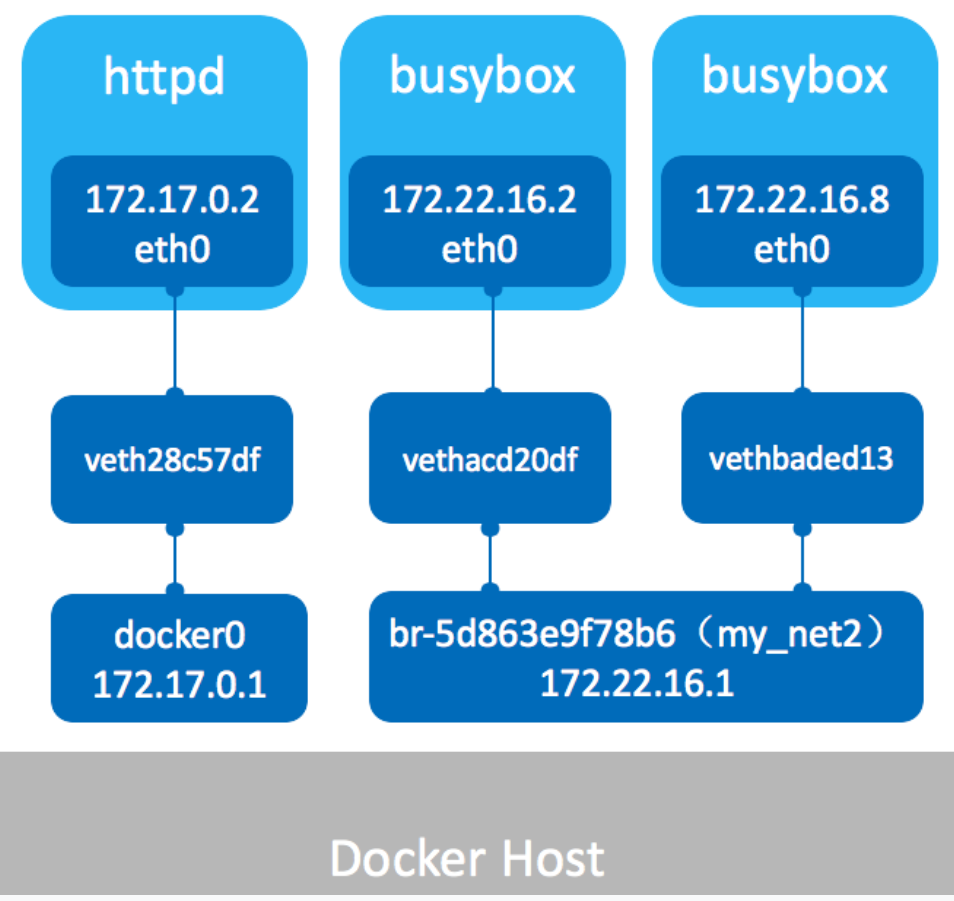
某个文档的内容
Docker网络bridge桥接模式,是创建和运行容器时默认模式。这种模式会为每个容器分配一个独立的网卡,桥接到默认或指定的bridge上,同一个Bridge下的容器下可以互相通信。
个人的不成熟意见
docker的桥接主要目的是解决跨命名空间的网络通信问题,因此使用了bridge的概念,虽然整体模式看上去与VM的桥接类似,但很关键的一点在于docker的桥接,并没有将宿主机接入到虚拟交换机中,因此仅实现了不同docker之间的互通性,而对外的网络访问使用的仍是NAT,宿主机的表现更像是一个上级路由器,而VM的桥接中物理机的表现更倾向于一个交换机
试一下docker bridge效果
开了三个docker,都是以默认形式开的
bridge name bridge id STP enabled interfaces
docker0 8000.0242f067143f no veth382d563
veth9ae432c
vethc95bd77
然后就发现docker0这个网桥上接了三个veth网卡,进容器一看,都是在docker0的172.18.0.1/24这个网段,还能互相ping通。这让我突然想起来比赛平台动态起docker的时候如果不把网桥直接进行隔离,岂不是不同用户的容器直接可能互相发现?
还有一点可以验证docker上网的形式是NAT,如果你在docker内去ping一个外部网络,然后在宿主机的出口监听网卡,就能发现外送的ICMP报文实际上使用的是宿主机的IP地址,而不是网桥内的局域网地址,也没有给bridge的docker分配一个新的dhcp地址
其他网络模式
VMware NAT
老生常谈,和正常的NAT没什么区别,物理机充当上层路由器,所有虚拟机藏在物理机后,对外不可见,且藏在物理机后的虚拟机可互联,画一个图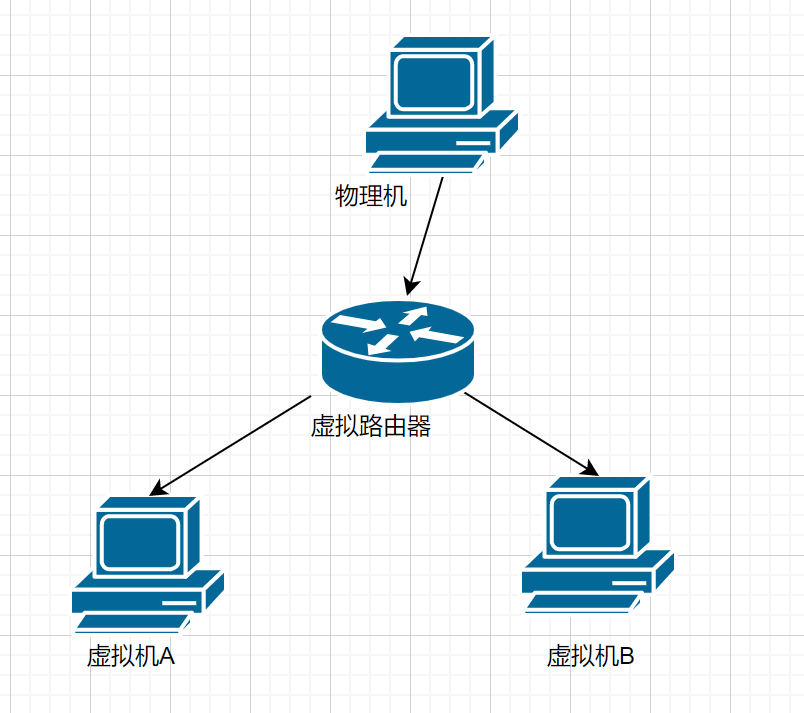
很好理解嗷,其实Docker的桥接在对外访问时,使用的即是NAT模型,但是名字却是桥接,即是这个坑了我好久。NAT在VMware中默认使用的是虚拟网络VMnet8,也是VMware安装时的三大虚拟网络之一
VMware host only
VMware三大虚拟网络最后一个,默认为VMnet1,就是搭了个包括主机在内的局域网,不连外网,也可以把主机剔除掉,就简单的搭一个虚拟机局域网
docker host
docker的三大初始网络服务之一
某文档里有这么一句
host模式类似于Vmware的桥接模式,与宿主机在同一个网络中,但没有独立IP地址。
这我就要说道说道了,你的Bridge相当于VMware的NAT,host再反过来相当于VMware的Bridge,这不给人整懵逼才有鬼呢
并且这里虽然说类似于VMware的桥接,但实际上和桥接差距还是很大,确实是和宿主机位于同一网络中了,但是并没有像桥接一样获得一份新的ip地址,而是表现的就像是宿主机上的应该服务,直接使用宿主机的ip和端口。创建该docker的时候,并没有创建新的网络命名空间,因此直接和宿主机位于同一网络命名空间下。比方说开一个mysql的docker,那他的表现就和主机上直接开一个mysql服务的表现差不多,不过这个mysql还被docker再包装了一层,被日了不会导致整个机子被日穿。
docker none
docker三大初始网络服务的最后一个,直接啥网不配,也不向外连接,适合自己搭着在本地玩。也可以自己起了之后再自己进去配网络
docker container
docker一共有四种网络模式,但是安装docker的时候之后安装上述三种默认服务。container模式就更加玄幻了,把已有容器的网络命名空间与新建容器共享,就像是把原有容器作为宿主机,新容器以host形式启动一样,所以这个网络服务不会在docker安装的时候安装在宿主机上,很合理。
TUN/TAP虚拟网卡
以前研究clash流量接管的时候就已经接触到了这两个玩意了,但一直没搞清楚是什么东西,这次做实验的时候有一步vpn的实现原理,顺便学习了一下
TUN和TAP的区别仅在于一个工作在三层一个工作在二层,TAP相较TUN能够多出一层链路层,就有获取ARP协议之类的能力。和传统的网卡不同,传统网卡连接的是内核协议栈和物理网络接口(网线),而虚拟网卡连接的是内核协议栈与用户程序
以tun为例,当用户程序创建tun虚拟网卡时,同时会打开/dev/net/tun这个文件接口,而主机上则会多出一块tunX的网卡,为了便于理解,可以认为这时用户程序是另一台主机,这样子虚拟网卡的表现也就类似于物理网卡,连接内核协议栈与外部网络,这时/dev/net/tun这个文件表现的就像是用户程序模拟出的主机上的一张网卡,当我们向其中写入时,就是向主机的tunX网卡发送数据包,而主机从tunX网卡发出数据包时,就可以在用户程序打开的/dev/net/tun文件中读到
可以把tun/tap看成数据管道,它一端连接主机协议栈,另一端连接用户程序
TAP因为多了一层arp,表现的更为像一台独立的主机,qemu的桥接模式据说就是使用的TAP网卡将虚拟机模拟成一台网络上完全独立于物理机的机器
vpn的简单原理
vpn分为client和server两端,client和server均在主机上建立一块tun卡,并处于同一网段。
client新建一条路由表,将需要访问的内网ip段指向虚拟网卡,在client主机访问内网ip时,即可将流量导到tun卡上。
tun卡按照之前的说法,会将流量发送vpn client程序上,vpn client再把数据加密打包到tunnel中,通过socket连接发送到vpn server的监听端口上。
vpn server收到数据后解包解密,写/dev/net/tun,表现的像主机在tun网卡上收到了来自client的请求,然后在内核协议栈中决定路由,从对应接口发送到内网中。
内网响应报文回送给vpn server,由于目的地址是client的tun卡ip,因此根据路由表会发送到server的tun卡上,server主机同理会在server程序中获取到返回包,通过socket返回给client。
client主机在client程序中收到返回包时,再进行写/dev/net/tun文件的操作,最终client主机在tun网卡上收到返回包
clash tun
写到这又想起之前研究switch联机时的clash tun流量接管方案了,也就是把路由表改掉把所有流量导到tun网卡上,然后clash就能获取到全部流量进行转发吧
参考链接
理解桥接bridge和dhcp的原理 讲的蛮清楚但总觉得有几个点是错的?
Docker网络:bridge桥接模式 有点坑的文档
Docker的四种网络模式Bridge模式
探索 Docker bridge 的正确姿势,亲测有效!
云计算底层技术-虚拟网络设备(tun/tap,veth) 图画的很详细易于理解,好文章