EBPF入门
记录一下最近入门eBPF的笔记,用于加强印象(以及偶尔点开博客发现又有一个月没有更新了),国庆肯定是有点小混了,然后就是感觉有很多东西也懒得记了,难得学点东西,并且感觉是一个比较新的技术,稍微写点。
学到目前主要是靠Isovalent家的这本Learning eBPF,写的脉络也可能也就大致和书的脉络一致。
基本概念
什么是ebpf,应该不会有人什么都不会就依赖我的博客入门的吧?本文所有内容均默认读者拥有最基础的基础,不会对太简单的东西进行过分的解释。
就我个人理解,ebpf是linux内核提供的一个扩展接口,允许用户以较低的开发成本对内核行为进行监控和修改,相较于内核模块的不稳定和对各版本内核需要单独维护,ebpf提供了较为统一的接口,使得一定情况下ebpf甚至能做到一次编译,四处运行(CORE)。
ebpf程序运行在内核的虚拟机中,其安全性在一定程度上拥有保障,且ebpf程序在加载进内核前会受到verifier的检查,以确保该程序的安全性。网上经常会说,该技术就之于内核就像javascript之于浏览器,提供了一种用户自行开发运行代码的接口。并且ebpf也具有热拔插,及时更新,在内核中没有上下文切换开销等一系列优点,总而言之,就是非常先进。
以及,ebpf的能力已经远远突破了bpf所谓的包过滤,所以这就是单纯的一个名字,而非字面意义上的扩展的伯克利包过滤器
cilium中有一张图给出了ebpf可以在内核插桩的各种位置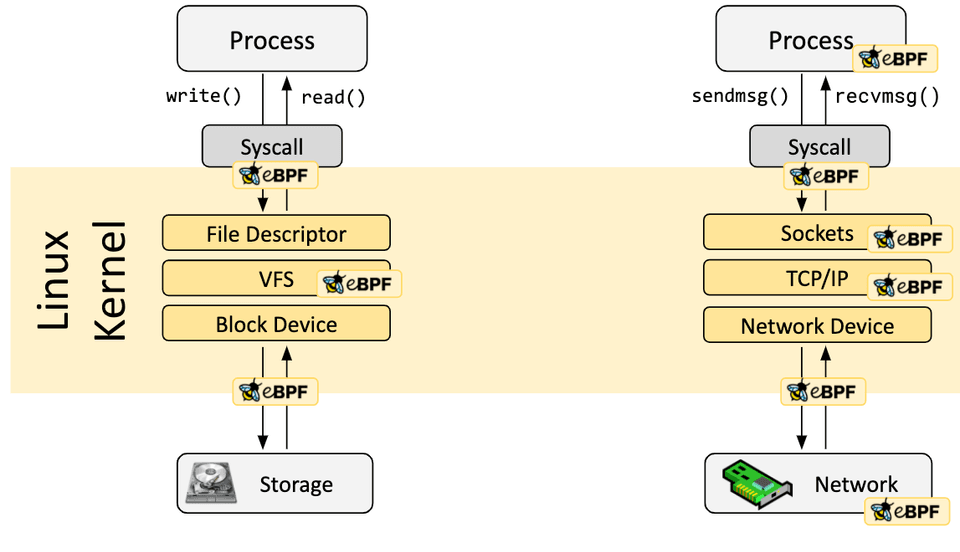
可以看到,ebpf可以附着在系统调用发生前后,网络事件,文件系统事件,甚至直接附着到网卡等硬件设备上。除此之外,即使预定义的hook不存在,ebpf也可以通过创建内核探针(kernel probe)的手段附着在几乎内核的任何地方
ebpf应用结构
一个完整的ebpf程序分为两部分,用户态程序和内核态程序,其中内核态程序又可以分为program和map两部分。program可以附着(attach)到内核运行的各个阶段,对内核中的事件进行观测响应,并通过map与用户态程序进行数据传递。下图也是从cilium处拿到的BCC框架的运行示意图
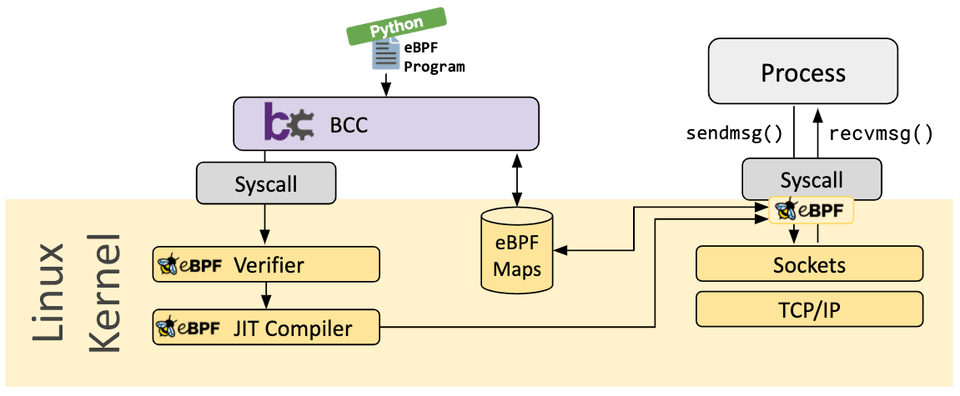
ebpf的内核态程序一般是由BPF字节码构成的,当ebpf程序被加载进内核时,内核再使用即时编译(JIT)将ebpf程序转换为机器码,在内核中运行。就目前的情况而言,开发ebpf的内核态程序的语言仅有c和rust,仅这两个语言的编译器支持将目标代码编译到ebpf字节码。(一开始还以为可以用go开发全部,呜呜)
开发框架
用户态程序的开发选项却很多,比如上图所示的的BCC,可以用python开发用户态程序,并且还优化了一点写C的逻辑,添加了一些新的Marco,可以写一些有点伪C的代码,最后BCC在编译的时候会优化为正常C代码。go写的ebpf go则是纯go实现的ebpf库,不过同样的,也只能写用户态程序。
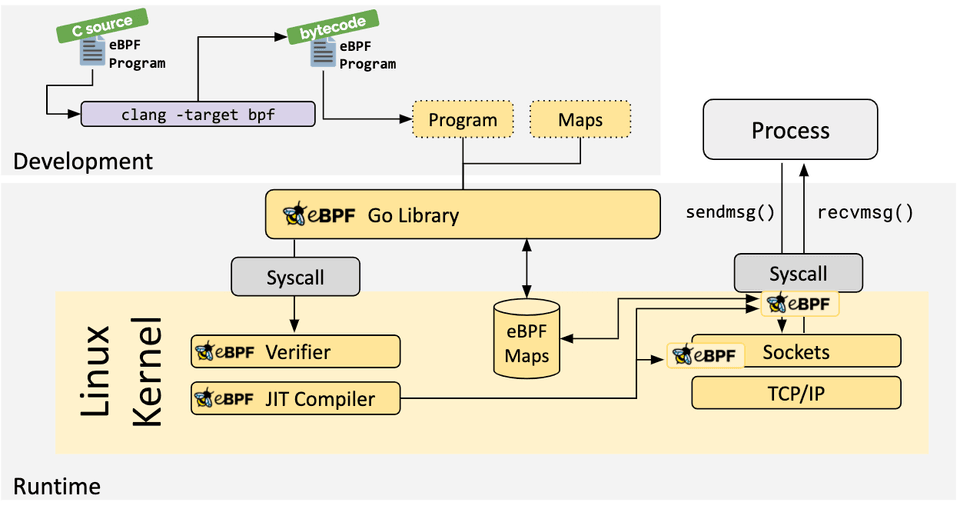
框架的作用是封装好了与bpf系统调用的交互,让用户可以直接对bpf程序进行加载,同时对ebpf map的数据结构进行解析,能够方便的直接使用map与ebpf程序进行交互。如上图,ebpf go使用clang将C源码编译到ebpf字节码,同时从中提取出ebpf program和map,开发者就可以直接使用解析到go数据结构的program和map进行操作,进一步降低开发难度。(但是C源码还是得自己写。。)
由于上述框架均需要最终将C代码编译成ebpf字节码,因此还是依赖于clang和llvm,llvm的版本区别在一定程度上可能会影响生成的ebpf字节码的兼容性。
ebpf程序
先从一个类似hello world的例子开始,虽然不是很HelloWorld。。。
接下来的代码都是抄的,代码不出意外的话应该大部分抄自learning-ebpf,虽然目前这份代码是从ebpf-go的文档里抄的。。。使用的开发框架即为ebpf go
内核程序
如下为一份ebpf内核程序的C代码,不包含用户程序
//go:build ignore
#include
#include
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__type(key, __u32);
__type(value, __u64);
__uint(max_entries, 1);
} pkt_count SEC(".maps");
// count_packets atomically increases a packet counter on every invocation.
SEC("xdp")
int count_packets() {
__u32 key = 0;
__u64 *count = bpf_map_lookup_elem(&pkt_count, &key);
if (count) {
__sync_fetch_and_add(count, 1);
}
return XDP_PASS;
}
char __license[] SEC("license") = "Dual MIT/GPL";
之前有提到过,ebpf程序是分为program和map两部分的,而对于这段C代码,pkt_count即为map,而count_packets即为program。一个源文件中如果定义了多个函数,那么该文件编译出来的ebpf字节码就包含多个program,同理,也可以包含多个map。
ebpf program
实际上,并非一个C文件编译出来的ebpf字节码被称为一个program,而是其中的一个函数会被成为一个program,然后用户再选择将该program attach到内核的哪个位置。如果划细一点,可以认为文件中的一个函数是一个program。也就意味着,一份ebpf的C源码可以包含多个ebpf程序,然后用户也可以将其attach到内核的不同位置
比如这里count_packets上的Marco SEC("xdp"),意味着将该ebpf program attach到xdp上,在网络报文抵达时进行处理。
可以使用bpftool对当前机器上的ebpf程序进行观测,bpftool prog list会展示当前所有的ebpf程序,每个程序在加载时会被分配一个id,然后可以使用bpftool prog show id <id> --pretty展示对应程序的详细信息。
一个可能的信息如下所示
{
"id": 540,
"type": "xdp",
"name": "hello",
"tag": "d35b94b4c0c10efb",
"gpl_compatible": true,
"loaded_at": 1659461987,
"uid": 0,
"bytes_xlated": 96,
"jited": true,
"bytes_jited": 148,
"bytes_memlock": 4096,
"map_ids": [165,166
],
"btf_id": 254
}
需要注意的是,同一个ebpf程序是可以被多次加载进内核的,其名称也可以相同,所以一般使用id对ebpf程序进行唯一识别。uid是指加载该程序的用户id,type指该程序被attach到了什么地方,map_ids保存了这个程序所引用的bpf map,tag是程序的哈希,因此同一个程序多次装载进内核时也会拥有相同的tag。
ebpf map
ebpf map是内核程序与用户程序沟通的桥梁,用户程序可以往map中写入数据以调整内核程序的设置,内核程序也可以将得到的数据交由用户程序进行处理或输出。
ebpf map有多种数据类型,常见的如array数组,hash表(字典),ring buffer等。
从如上代码中使用SEC(".maps")宏定义了一个map数据结构,并设置了其为一个array,名为pkt_count。ebpf map可以用bpftool map list命令进行枚举,可能的值如下
254: hash flags 0x0
key 8B value 8B max_entries 4096 memlock 331776B
255: perf_event_array name printf flags 0x0
key 4B value 4B max_entries 2 memlock 4096B
类似的,map也会在创建的时候分配唯一的id,然后是他的类型,key和value的大小,条目数量之类的数据。
ebpf program和ebpf map并不是绑定的,从之前的开发框架图中也可以看到,ebpf map在内核中是单独放置在一个位置的。一个map可以被多个program引用,一个program也可以引用多个map。ebpf程序需要使用内核提供的helper函数去访问map,而不能像一个成员变量一样去直接访问。用户态程序则可以使用系统调用发起指定map的访问。
用户程序
package main
import (
"log"
"net"
"os"
"os/signal"
"time"
"github.com/cilium/ebpf/link"
"github.com/cilium/ebpf/rlimit"
)
func main() {
// Remove resource limits for kernels <5.11.
if err := rlimit.RemoveMemlock(); err != nil {
log.Fatal("Removing memlock:", err)
}
// Load the compiled eBPF ELF and load it into the kernel.
var objs counterObjects
if err := loadCounterObjects(&objs, nil); err != nil {
log.Fatal("Loading eBPF objects:", err)
}
defer objs.Close()
ifname := "eth0" // Change this to an interface on your machine.
iface, err := net.InterfaceByName(ifname)
if err != nil {
log.Fatalf("Getting interface %s: %s", ifname, err)
}
// Attach count_packets to the network interface.
link, err := link.AttachXDP(link.XDPOptions{
Program: objs.CountPackets,
Interface: iface.Index,
})
if err != nil {
log.Fatal("Attaching XDP:", err)
}
defer link.Close()
log.Printf("Counting incoming packets on %s..", ifname)
// Periodically fetch the packet counter from PktCount,
// exit the program when interrupted.
tick := time.Tick(time.Second)
stop := make(chan os.Signal, 5)
signal.Notify(stop, os.Interrupt)
for {
select {
case <-tick:
var count uint64
err := objs.PktCount.Lookup(uint32(0), &count)
if err != nil {
log.Fatal("Map lookup:", err)
}
log.Printf("Received %d packets", count)
case <-stop:
log.Print("Received signal, exiting..")
return
}
}
}
用户态程序会随着你使用的开发框架而有所改变,对于ebpf go而言,需要使用bpf2go工具将C源码进行编译(内部还是用的clang和llvm),但是bpf2go会在编译过程中将对应的数据结构提取出一份go代码(bpf skeleton),用于后续使用。比如如上代码中使用的counterObjects,就是对应了之前的C代码中的内容,此处objs包含了整个C文件的map和program,objs.CountPackets就是count_packets这个ebpf程序,而objs.PktCount对应的是C中的pkt_count map
在bpf2go生成的go文件中,也可以看到相关的代码
// counterObjects contains all objects after they have been loaded into the kernel.
type counterObjects struct {
counterPrograms
counterMaps
}
...
// counterMaps contains all maps after they have been loaded into the kernel.
type counterMaps struct {
PktCount *ebpf.Map `ebpf:"pkt_count"`
}
...
// counterPrograms contains all programs after they have been loaded into the kernel.
type counterPrograms struct {
CountPackets *ebpf.Program `ebpf:"count_packets"`
}
这个go程序也没啥好说的,对应的程序加载进了内核,然后attach到了XDP上去嗅探流量,最后从map中读取数据。框架的好处就是一个函数直接加载进内核,一个函数直接attach上去,map也不用手动load,全都框架一键配置完成。
这些操作都是对bpf相关系统调用的封装,具体的细节交由bpf syscall这一节完成
bpf() syscall
之前提到过,bpf内核程序通过helper函数与内核互动(因为内核程序虽然运行在内核,但是还是有一层虚拟机类似的隔离机制,防止把内核打爆,但这个虚拟机的开销应该是远小于系统调用的上下文切换的),而用户态程序还是通过系统调用和bpf内核程序交互,其中最主要的交互方法就是bpf()这个系统调用。
其函数签名如下
int bpf(int cmd, union bpf_attr *attr, unsigned int size);
第一个值cmd指明了进行的操作类型,从书里面抠一张图出来直接展示各种cmd值
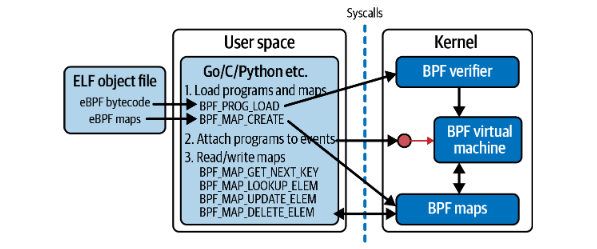
可以看到,加载bpf program和bpf map是分开的两个命令,如果是手搓系统调用的话,需要手动将program和map分别加载进内核。attach时根据attach的位置可能会调用其他的系统调用。
但是如果从头跟起的话,可以看到在进行BPF_PROG_LOAD和BPF_MAP_CREATE命令之前,会先使用BPF_BTF_LOAD将BTF数据结构加载进来。
BTF
BTF全称BPF Type Format,用于指定bpf程序的数据结构,包括具体的每个数据的大小和偏移等信息,该信息被内核用于解析程序中的结构,后续的map create和program load调用中提供的参数都是依赖于从BTF中读取的信息。
BTF数据同时使得bpf程序可以在不同的内核上一次编译,四处运行(compile once,run everywhere),而无视不同内核间数据结构可能的差异,该技术就是通过BTF以及对应的重定向表实现的。bpf程序的入参的结构体在vmlinux.h中定义,然而该结构体可能在不同的linux版本中发生变化 ,BTF可以在编译时记录对应的结构体信息,生成object文件,最后在object文件加载进内核即时编译后和当前机器对应
然而,bpf相关系统调用却没有program unload和map unload相关的指令,这是因为ebpf程序的unload是通过引用计数来完成的,当用户态程序使用BPF_PROG_LOAD指令加载内核程序后,系统调用会返回一个对应的fd,此时对应的引用计数就会加一,当程序退出时,fd被释放,引用计数减一。当引用计数为0时,ebpf程序被释放,对bpf map也是同理。
ebpf verifier
这一章没仔细看,毕竟写代码的时候遇到bug了再去临时解决。
verifier用于评估一个ebpf program是否能够安全运行。其实光看描述就能猜出来,这里的操作很类似于之前学的南大的那个程序分析课程,只不过之前的课程是对java源码做分析,而这边则是对字节码和寄存器值进行分析。
既然是确保程序的安全性,自然做的是一个safe的分析,一个may analysis,即考虑所有的可能性,有一种不安全的情况即认为不安全。就是当一个值可能是1也可能是2时,将结果做并集,认为其为(1,2),如果做sound的分析则是确保有错误才会输出,即将结果做交集集,直接认为结果不可知
书上有一个例子,使用bpf_map_lookup_elem不检查返回的p是否为null,verifier就会抛出一个map_value_or_null的错误,即该函数调用结果可能返回空指针或map entry,做并集后值包含空指针,抛出错误,加上一个p != 0的判断后再对p进行解引用,此时显式的排除了p为0的可能性,即可通过verifier的校验。
ebpf program type
ebpf程序可以attach到许多位置,对应不同的attach位置,ebpf程序获取的入参,能够调用的helper函数均会有所差异。
如在网络接口上进行网络嗅探的ebpf程序,就无法调用bpf_get_current_pid_tgid这个获取当前调用者pid的helper function。
kprobe/kretprobe
kprobe和kretprobe是比较常见的hook点,分别对应内核函数的调用和退出。kprobe可以获取函数的入参,而kretprobe可以获取函数的返回值。
fentry/fexit
在更高版本的内核中,fentry和fexit两个hook点也能实现对函数调用和退出的hook,相较于kprobe/kretprobe更为先进,fexit不仅可以拿到函数的返回值,也能拿到函数的入参。
tracepoint
tracepoint是内核中的一系列标记,对应着内核中各种类型的事件,相较于kprobe,tracepoint更为稳定,可以通过查看/sys/kernel/tracing/available_events查看内核中的tracepoint。tracepoint的参数会随着不同的tracepoint变动,在未使用BTF的情况下,可以手动查看/sys/kernel/tracing/events下对应tracepoint的format文件查看入参数据结构,然后手动搓一个对应的结构体。这样子搓出来的结构体在内核数据结构发生变化时就会变得不能用,并不具有普适性
这里有一篇如何找tracepoint及其对应参数格式的文章
ebpf/libbpf 程序使用 tracepoint 的常见问题
BTF-Enabled tracepoint
如果能用BTF的话,直接在声明宏的时候声明为一个BTF的tracepoint,就可以直接用trace_event_raw_<tracepoint_name>解决数据结构问题,并且这个结构体是直接从当前机器的vmlinux.h拿,跨不同内核也跑得起来
用户态attachment
ebpf程序也可以hook到用户态程序下,可以使用uprobe/uretprobe对用户态函数进行hook,不过需要指定目标程序使用的动态链接库,如SEC("uprobe/usr/lib/aarch64-linux-gnu/libssl.so.3/SSL_write") hook住了libssl中的SSL_write函数。
可以用nm -D x.so命令查看.so的导出表。
这就会导致用户态的hook存在多个问题,如果用户态程序是静态编译的,不会使用这个.so,那么hook就不会生效,且由于需要指定lib路径,这个设置针对每个机器都是独立的,迁移后需要重新修改并编译,容器会有一套自己的libc,所以该hook也无法对容器内的调用进行监控,并且不同语言的传参形式不一样,C使用寄存器栈混合传参,而go则使用栈传参,使得不同应用在同一个hook处传递给ebpf程序的参数格式会有所不同等。
sockets
bpf一开始就是被用于进行包过滤的,ebpf自然也在该方面拥有着大量的应用。BPF_PROG_TYPE_SOCKET_FILTER类型的程序可以对socket数据进行审计,然而其并不能像一个真正的filter一样对数据进行删改,而只是简单的拿到了一份copy
traffic control
缩写TC,就是以前经常能看到但是不知道是在说什么的程序类型。
好像涉及了一个完整的linux子系统,太复杂了捏
XDP
最最常见的ebpf流量控制程序类型,express data path,可以附着一个网络接口(interface)上,虚拟网卡也可以,甚至在某些网卡的硬件支持下可以直接在网卡上运行,节省CPU算力。每次数据包到达的时候XDP程序就被触发,并且XDP程序的返回值会影响内核对这个数据包的行为,如放行、丢弃或者转发。
不过一个接口上只能附着一个XDP程序
Cgroup
control group,linux下用于进行限制和隔离的手段,docker之类的容器就是用cgroup进行隔离来实现的。可以通过对cgroup的控制实现对docker等容器的控制。
还有些别的program type,不过感觉不怎么常用,就不一一例举了
ebpf for networking
XDP
XDP在数据包抵达网络栈之前对数据包进行预处理
XDP除了可以影响内核对数据包的处理,也可以修改数据包,XDP attach在网卡上,所以收到的是最原始的数据报文,需要从链路层、IP层一层层解析上去。如果网卡支持ebpf,可以直接在网卡上运行ebpf程序,不消耗CPU算力。书中给出了一个改数据包的mac和IP地址,然后直接将这个包从入口网卡发出的负载均衡的小例子
TC
traffic control则需要在数据包进入网络栈后对其进行处理,因此,TC可以获取到一个名为sk_buff的指针,为内核在网络栈中处理数据包的格式,可以获取更多的信息,更好操作。以及XDP是在每次包到达时触发,只能处理流入流量,而TC可以处理流出流量
ebpf for security
可以在syscall的入口打hook,但是问题在于系统调用时需要从用户态中去copy指针的值,会有一个条件竞争的时间,攻击者可以去竞争ebpf的检查时间和实际内核copy参数的时间去修改,使得ebpf程序拿到的数据和实际调用过程中的不一致。

虽然也可以,但是攻击者也可以再竞争改回来,并且在fexit时操作已经完成了,无法对实时事件进行处理,只能进行一个异步的报警。(不过应该可以直接attach到各个实际的系统调用上就可以绕过这个问题,但这种情况下比较麻烦的就是对应每个系统调用要写一堆代码吧)
为了解决这种问题,就需要引入LSM(Linux Security Module)这个模块,该模块可以在内核从用户态获取了数据,但没有实际执行系统调用前对参数进行检查,并且程序的返回值可以影响该调用的执行与否