tabby使用入门
在坐完了CodeQL的牢之后,尝试使用另一个高级一点的工具
整体的使用难度并不是很高,主要是顺便把windows上的一些乱七八糟的java环境相关的事情重新理了一遍。把一些垃圾文件清理掉了
(用了半天感觉windows跑java不行)
说起来搜这个tabby的时候搜到了另一个叫tabby的终端,看了一下挺好看的就替换掉了非常不行的cmder和git bash(唯一缺点是启动需要个两三秒)。然后就出现了用tabby在命令行跑tabby的操作
java相关环境配置
挺简单的,去下个neo4j Desktop,然后记得把发的垃圾邮件退订。一路安装就行了,desktop非常的图形化,比较友好
然后apoc的插件似乎也不需要手动安装,在plugins那一栏可以直接自动安装。就是不知道为什么简单的装了个插件建了个数据库就用掉了我5G的硬盘呢?
然后neo4j的话因为我下的新版,所以需要Oracle java11。又临时去Oracle下了个。之后对整个电脑的java环境进行了一个检查
无非也就是些注册表和环境变量的检查。现在java早就已经不使用什么远古java home这种手动配置方案了,会在安装时直接在系统的PATH里给你塞一个环境变量,还要置顶。。。
一般来说是这个路径C:\Program Files\Common Files\Oracle\Java\javapath,然而这个路径实际上是一个软链接,软链接到这个目录下的一个java_target_xxx。。。。这个目录里面塞了一个java一个javac和一个javaw?那为什么不直接连接到java安装目录的bin下?
简单改造,把这个目录删了直接环境变量设到java安装目录。。希望不会出大问题
然后还有一个遗留问题。我的burp是远古时期的某个印度破解版。只兼容jdk8,如果我把整体调整到11他是跑不起来的。并且还不支持openjdk,只能用Oracle的。
但是我神奇的发现修改环境变量并不会导致双击打开jar包的jdk更改,然后感觉应该是注册表,搜了一下,果然是注册表中的javaw.exe决定了这个操作。这样子就能在环境变量是java11的情况下继续用我的远古burp了。。。(还是找个时间升级一下好了)
编译tabby
tabby只支持jdk8,所以不要用jdk11
编译配置都写好了,用的是gradle,应该是类似于maven的东西。但是我默认的jdk8u311在运行的时候会报一个非常奇怪的错误
Java home is different.
Expecting: 'D:\Java\jdk\jdk1.8.0_311' but was: 'D:\Java\jdk\jdk1.8.0_311\jre'.
Please configure the JDK to match the expected one.
谷歌的话处理方案多种多样,但简单的看了几眼都和我的情况不一样
最后在某个不起眼的角落发现了一个低赞回答
IntelliJ broke when I copied tools.jar to a jre/lib, attempting to make hot attach work.
说起来我之前因为某个不知名的原因好像真的做过这个操作。。。然后把jre下面的tools.jar删掉就可以了。。。
以及IDEA默认的maven和gradle的目录都在用户的家目录下。并且不知道为什么gradle那个目录上来就直接3G,看了下有一个cache目录就2G。。。不知道都在干些什么,硬盘真有点吃紧了
尤其是我的C盘已经有点不堪重负了。全部转移到D盘,并且对项目的配置进行修改。这里也很坑,修改只对当前项目有效,也就是之前的项目全部得单独配置。。。最坑的还不是这里,新开项目仍然是按照家目录的默认配置,需要从File->New Project Setup->Seting For New Projects处再额外修改才能确保未来不被坑
这里有一个新的坑。GitHub上的release的代码事实上是有点旧的,一些在已经关闭的issue中修复的问题实际上是在最新的release之后,我就说我怎么自己编译的还跑不通。。。
然后直接从主页拉最新的代码进行编译
然后刚好撞上tabby更新将命令行参数更改到配置文件参数,但是实际上的help页面还是对应的命令行版本,且有一个isJDKOnly选项不能正常用的小bug。。。以及isSaveOnly选项给去掉了,跑完直接往数据库里写。搞得我一开始莫名其妙了半天然后自己看了下代码发现有问题再魔改了一下源码。不过这样子就可以直接在IDEA里面改配置文件直接运行spring app,不像原来一样需要打一个jar包命令行运行。
打jar包命令行运行的话需要把jar包和rules和config目录放在同一级,否则也会出现找不到文件之类的错误
然后不要高估自己的小笔记本的性能。。。。
今天试了一下单跑一个isJDKOnly,数据库倒是在几分钟内写完了,但是将数据库导入log4j花了一个小时都没完成。。。并且CPU占用一直100%,感觉要烧了。。。
被迫中断。然后从jdk里面选了个最大的rt.jar进行分析。倒是在十几分钟内把分析+导入数据库给完成了。然后就可以开始尝试写语句了
neo4j简单入门
上来会直接有一个提示命令可以查看数据库的基本逻辑关系。这对接下来的查询有很大的帮助CALL db.schema.visualization()
得到这样子的一幅图
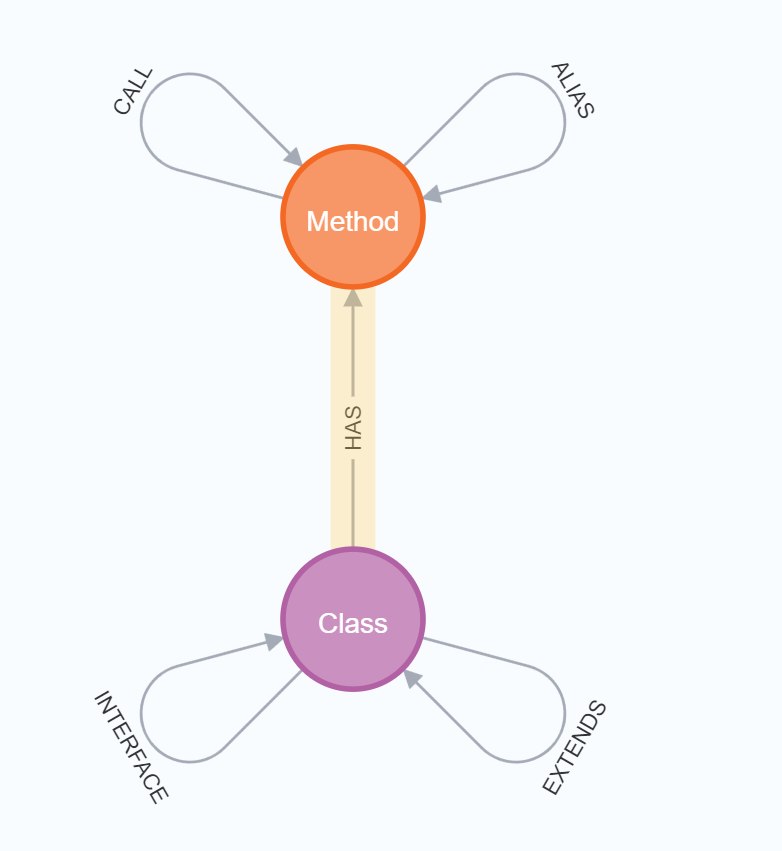
圈表示节点,线表示路径且有方向
目标是复现上次HFCTF的二次反序列化类,找到一个调用了readObject方法的get开头的方法
上次写过codeql之后感觉用起来上手就更快了
使用match语句定义变量,where语句添加约束,return语句返回结果。函数什么的暂时不学
使用括号来表示节点,-[]->表示路径关系
然后可以从图中看出类与类直接的关系是继承,方法与方法直接的关系是调用,别名问了下甫舟,就是只继承重写之类的操作。然后类中包含方法(实际上后面测试发现也有类包含类,应该是指在类中定义的类,而不是成员变量。tabby似乎并不能对类与成员变量之间的关系进行分析)
那么先写一个雏形出来
match (source:Method)-[:CALL|ALIAS]->(sink:Method)
where source.NAME =~ "get.+" and sink.NAME="readObject"
return * limit 10
其实这个语句就直接查出来结果了。。。。=~表示使用正则匹配,Method是有一个IS_GETTER属性的,然而get开头的方法并不等价于他就是getter,所以用正则直接匹配get开头的方法。说起来当初调试Hessain的时候就发现他的反序列化理论上是只调用getter但实际上没有很调通发生了什么但就是调用了这个不是getter的getObject。。。
然后为了保险和练习起见加一些buff
match (source:Method)-[:CALL|ALIAS*..3]->(sink:Method)
match (c:Class{IS_SERIALIZABLE:TRUE, IS_INTERFACE:FALSE})-[:HAS]->(source)
where source.NAME =~ "get.+" and sink.NAME="readObject" and source.PARAMETER_SIZE=0
return * limit 10
结果也不会有什么区别,不过条件拉的更满就更加的稳妥嘛
这里唯一需要记忆的语法就是*..n,猜也能猜出来是重复步长的意思
用起来上手还挺快的,没有codeql那么折磨,也可能是因为整体关系较为简单的缘故,所以精细程度什么的也就不如codeql精细了。所以这里就算找到了这个函数,也没发编写语句查看一下这个传入readObject的参数是否易失之类的。
还有上次susctf的那个寻找一个可序列化且存在一个成员变量为Object类型的类也没法实现